In "User Stories Applied", Mike Coen puts forward a method for estimating the cost of developing stories (or any other piece of work).
In summary:
* The development team get together with the customer.
* The customer describes a story.
* The developers quiz the customer until they are happy they understand the story.
* Each developer that wants to participate writes an estimate down.
* All developers show their estimates.
* The developer with the highest estimate states why they think it's so big.
* The developer with the lowest estimate states why they thing it's so small.
* The developers discuss the problem further until they're all happy they understand what's involved, and they estimate again.
The loop keeps going round until the team all have the same estimate, or they're happy to accept a compromise on one.
Once the stories are all estimated, they're put in a line of ascending cost and examined to make sure there are no discrepancies. If there are, then that story is re-stimated.
It works a treat, and the customers like it.
In fact they like it so much that they've come up with a variation...
Excluding the project manager, our customer team consists of two full time members and a number of people that work on our project only part-time. One slight issue is that over the last 18 months the full time members are becoming more a part of the Information Systems team and less in touch with 'The Shop Floor'. The part-time members help to ground them in the reality of the system.
On the other hand, the part time members aren't available to instantly evaluate new stories, and prioritise them accordingly.
So, once a week the customer team now get together in a 'Value and Take-up estimation'. It works in the same way as the developer estimates except the customer team are evaluating the value that a given story will add to the system, and then the take-up level expected for that part of the system in a scale of one to ten,
Obviously, the priority of a story is based on the combination of all three variables, Value / Take-up and Cost. Still, as a general rule, a story that scores high on Value and high on Take-up is going to be a story that will be prioritised very highly unless the cost is extortionate!
In fact the particular values may not be that important; there is no point discussing if a Value 8, Take-up 7 story is more important that a Value 7, Take-up 8 story on the basis of the raw values alone.
Rather it's the forum for the discussion of the values that provides the real insight, and allows everyone to have their input.
It's working to ensure that the team is working on what the whole customer team decide is the most important task, and not just the one with the loudest voice...
Technorati Tags: XP, Extreme+Programming, agile, software, development, programming, estimating, user+stories, software+development, Robert+Baillie
Wednesday, December 07, 2005
Friday, November 11, 2005
Firefox past 10 percent
According to this week's New Scientist, Firefox has managed to get more than 10% of the web browser market.
When I read that I was surprised.
It seems that readers of this blog are much more discerning than your average internet user. For some time now Firefox has been the browser used in more than HALF the requests to this site!
I'm sure that says more about bloggers and their readers than it does about this site in-particular...
When I read that I was surprised.
It seems that readers of this blog are much more discerning than your average internet user. For some time now Firefox has been the browser used in more than HALF the requests to this site!
| New Scientist report | Bobablog readers | |
| MSIE | 85.45% | 44.42% |
| Firefox / Mozilla | 11.51% | 51.44% |
| Safari | 1.75% | 1.56% |
| Netscape | 0.77% | 0.32% |
| Opera | 0.26% | 1.56% |
I'm sure that says more about bloggers and their readers than it does about this site in-particular...
Non-techie Tip of the Month
Sorry to still be way off topic, but I was given a beautiful gem of a tip today.
Have you ever accidentally written on a whiteboard with a permanent marker?
If so, you'll know how painful it is trying to remove it again with solvents. Far too much elbow grease required for my liking.
Well, we had one of those moments today and someone piped up with a glorious bit of help.
Simply write over the existing text with a proper whiteboard marker, then rub it off with a normal whiteboard rubber.
Zero effort and a clean whiteboard!
I promise that normal Oracle and PHP based services will be resumed soon...
Have you ever accidentally written on a whiteboard with a permanent marker?
If so, you'll know how painful it is trying to remove it again with solvents. Far too much elbow grease required for my liking.
Well, we had one of those moments today and someone piped up with a glorious bit of help.
Simply write over the existing text with a proper whiteboard marker, then rub it off with a normal whiteboard rubber.
Zero effort and a clean whiteboard!
I promise that normal Oracle and PHP based services will be resumed soon...
Tuesday, November 08, 2005
Subversion de-perversion
Mr Mason has done it again.
For those that use Subversion for their version control, Mike Mason's blog is a must subscribe. He doesn't post often, but when he does it's invariably useful. His latest post covers splitting and merging Subversion repositories. As usual, reading it leads to an "Of course that's how you it!" moment.
If you haven't already picked it up, his book, "Pragmatic Version Control with Subversion" is a great introduction to Subversion.
Technorati Tags: Subversion, version+control, CVS, VCS, SCM, Mike+Mason, Robert+Baillie
For those that use Subversion for their version control, Mike Mason's blog is a must subscribe. He doesn't post often, but when he does it's invariably useful. His latest post covers splitting and merging Subversion repositories. As usual, reading it leads to an "Of course that's how you it!" moment.
If you haven't already picked it up, his book, "Pragmatic Version Control with Subversion" is a great introduction to Subversion.
Technorati Tags: Subversion, version+control, CVS, VCS, SCM, Mike+Mason, Robert+Baillie
Monday, November 07, 2005
Questionable Search...
I know I've been quiet for a while, but I'm still here. There's things I'm going to get round to saying sooner or later, but a recent move has meant a distinct lack of internet access at home.
For now though... my referrer tracking uncovered a hit to the site from an unexpected search, one that I'm not sure how to deal with...
What does smug mean?
For now though... my referrer tracking uncovered a hit to the site from an unexpected search, one that I'm not sure how to deal with...
What does smug mean?
Friday, October 14, 2005
Things I have learned this week
A couple of friends and I were joking over the weekend that if we all learned one thing each, every day for a year, then at the end of the year we'd be able to release the book 'Over 1001 things that 3 people learned in a year'
Here's what I learned this week:
I cannot make any guarantee as to the accuracy or relevancy of any of the facts, nor will I compensate anyone for the loss of time spent reading them.
Here's what I learned this week:
- 08/10/2005: Cannon Street London Underground station used to have an ornate glass roof that was removed at the start of WW2. It was moved to the countryside to avoid bomb damage. The barn it was kept in was bombed a week later, completely destroying the glass roof. Cannon Street station remained virtually untouched throughout the whole of the war.
- 09/10/2005: Archduke Franz Ferdinand was assassinated in Sarajevo.
- 10/10/2005: The ship the Queen Elizabeth 2 is always written down with the number 2 rather than the roman numerals II. This is done in order to differentiate it from the Queen with the same name.
- 11/10/2005: The most abundant metal in the human body is calcium
- 12/10/2005: The most abundant bird in the world is the domesticated chicken. In 2003 the US ate 8.2 billion chickens, and if a chicken is grown for 7 weeks before being killed for meat, then in order for the 65 million people in the UK to be able to eat their average of 0.75 chickens a week then a total of 341.5 million chicken must exist at any given time in order to support the market.
- 13/10/2005: It's not enough to learn from your mistakes, you have to actually remember that you learnt from them and put those lessons into action.
- 14/10/2005: Whenever you find a gap in a test and you think "No, I won't put that test in, it'll never happen", it will happen, and it'll probably happen on the live system and give you a big headache.
I cannot make any guarantee as to the accuracy or relevancy of any of the facts, nor will I compensate anyone for the loss of time spent reading them.
Wednesday, October 05, 2005
Casting a table: variations on a theme
A heads up from William Robertson and I've taken yet another look at the TABLE command (which allows you to issue SQL against a PL/SQL table as if it was a database table). As he points out here, it seems that the TABLE cast has trouble working out the data type when you're doing a SELECT *, but can often work out the data type for the same statement with the column list specified.
Obviously, if I hung around on Ask Tom or Metalink I'd find it much easier to find these nuances out... and I'd do it in a far less public way. But hey, I'd probably forget it then, wouldn't I! ;-)
Anyway, I've put together 3 scripts that some illustrate slight variations that are available. Note I've included DROP statements to get rid of any nasty residue, not to imply that you should drop these types in any real application.
So, first up is a variation that uses a SELECT * and a TABLE + CAST selecting from a PL/SQL table of a primitive datatype
The second variation uses a SELECT column list, and a TABLE selecting from a PL/SQL table of a primitive datatype. Note that the column name is inferred.
The last variation uses a SELECT column list, and a TABLE selecting from a PL/SQL table of objects. Note that the column name is no longer implied, but there is a requirement to construct objects in order to use this variation.
More investigation will take place, and I'm sure this won't be the last post on the topic!
Technorati Tags: , Robert+Baillie, oracle, table, cast, software+development, software, database, 9i, ask+tom, metalink
Obviously, if I hung around on Ask Tom or Metalink I'd find it much easier to find these nuances out... and I'd do it in a far less public way. But hey, I'd probably forget it then, wouldn't I! ;-)
Anyway, I've put together 3 scripts that some illustrate slight variations that are available. Note I've included DROP statements to get rid of any nasty residue, not to imply that you should drop these types in any real application.
So, first up is a variation that uses a SELECT * and a TABLE + CAST selecting from a PL/SQL table of a primitive datatype
SET SERVEROUTPUT ON SIZE 100000
CREATE TYPE char_table_type AS TABLE OF VARCHAR2(1);
/
DECLARE
--
char_table char_table_type;
--
CURSOR cur_tab IS
SELECT *
FROM TABLE( CAST( char_table AS char_table_type ) );
--
BEGIN
--
char_table := char_table_type('A','B','C','D','E','F','G','H','I');
--
FOR tab_rec IN cur_tab LOOP
DBMS_OUTPUT.PUT_LINE( tab_rec.column_value );
END LOOP;
--
END;
/
DROP TYPE char_table_type;
/
The second variation uses a SELECT column list, and a TABLE selecting from a PL/SQL table of a primitive datatype. Note that the column name is inferred.
SET SERVEROUTPUT ON SIZE 100000
CREATE OR REPLACE TYPE char_table_type AS TABLE OF VARCHAR2(1);
/
DECLARE
--
char_table char_table_type;
--
CURSOR cur_tab IS
SELECT column_value
FROM TABLE( char_table );
--
BEGIN
--
char_table := char_table_type('A','B','C','D','E','F','G','H','I');
--
FOR tab_rec IN cur_tab LOOP
DBMS_OUTPUT.PUT_LINE( tab_rec.column_value );
END LOOP;
--
END;
/
DROP TYPE char_table_type;
/
The last variation uses a SELECT column list, and a TABLE selecting from a PL/SQL table of objects. Note that the column name is no longer implied, but there is a requirement to construct objects in order to use this variation.
SET SERVEROUTPUT ON SIZE 100000
CREATE TYPE char_table_row AS OBJECT ( letter VARCHAR2(1) );
/
CREATE TYPE char_table_type AS TABLE OF char_table_row;
/
DECLARE
--
char_table char_table_type;
--
CURSOR cur_tab IS
SELECT letter
FROM TABLE( char_table );
--
BEGIN
--
char_table := char_table_type( char_table_row ('A')
,char_table_row ('B')
,char_table_row ('C')
,char_table_row ('D')
,char_table_row ('E')
,char_table_row ('F')
,char_table_row ('G')
,char_table_row ('H')
,char_table_row ('I') );
--
FOR tab_rec IN cur_tab LOOP
DBMS_OUTPUT.PUT_LINE( tab_rec.letter );
END LOOP;
--
END;
/
DROP TYPE char_table_type;
/
DROP TYPE char_table_row;
/
More investigation will take place, and I'm sure this won't be the last post on the topic!
Technorati Tags: , Robert+Baillie, oracle, table, cast, software+development, software, database, 9i, ask+tom, metalink
Friday, September 30, 2005
If I had a hammer...
I'm sure that pretty much every experienced developer out there has heard the proverb:
Well, I've heard a few variations on the theme and so I've decided to start collecting them...
Anyone got any more?
- If the only tool you have is a hammer, then everything's a nail.
Well, I've heard a few variations on the theme and so I've decided to start collecting them...
- Sometimes it's just a nail, and all you need is a hammer.
- Don't ignore your hammer just because you heard someone else hit their thumb with theirs.
- When you're in the market for a new tool, make sure you're not buying yet another hammer.
- You can enhance the usefulness of your hammer by adding a chisel.
- A Rotary Electro-pneumatic hammer delivering 4600 hammer blows a minute is still just a hammer.
Anyone got any more?
Wednesday, September 28, 2005
The In Thing - Simplified
I've had a few people visit the site looking for some help on the Oracle 9i TABLE command. With this, you can issue SELECT statements against PL/SQL tables.
Now, previously I'd posted about the self same command, in a series of posts here:
http://robertbaillie.blogspot.com/2005/07/in-thing.html
http://robertbaillie.blogspot.com/2005/07/in-thing-example.html
http://robertbaillie.blogspot.com/2005/07/in-thing-simpler-example.html
Soon, I plan to put a few more notes together, starting from a simpler example. But for now I'll just thank Amis for the post here, which has pointed out a complexity in my own example that I didn't realise...
For some reason, the TABLE command cannot work out the data type of variable passed to it, and so will tend to throw an exception:
ORA-22905: cannot access rows from a non-nested table item
As I'd only ever done this when working with package, I previously worked around this by coding a function that returns the content of the relevent package variable. TABLE has no problem working out the datatype returned from a function.
It turns out I could have got away with just a simple CAST.
E.G. SELECT * FROM TABLE( CAST( table_variable AS table_type ) )
So, with that in mind, the first 'In Thing' example becomes this:
The Example:
In order to have something to access, we need the tables and data:
In order to perform the cast we need to declare a type for the row in the table, and then the table type itself:
Then we define the package that will perform the cast.
We have the following functions
Finally, we have some code to run the GET_PRODS_BY_NAME function and return its set of values.
And the output:
Disclaimer: I've not yet managed to test this out with access from a PHP layer...
Technorati Tags: Robert+Baillie, oracle, table, cast, software+development, software, database, 9i, Amis
Now, previously I'd posted about the self same command, in a series of posts here:
http://robertbaillie.blogspot.com/2005/07/in-thing.html
http://robertbaillie.blogspot.com/2005/07/in-thing-example.html
http://robertbaillie.blogspot.com/2005/07/in-thing-simpler-example.html
Soon, I plan to put a few more notes together, starting from a simpler example. But for now I'll just thank Amis for the post here, which has pointed out a complexity in my own example that I didn't realise...
For some reason, the TABLE command cannot work out the data type of variable passed to it, and so will tend to throw an exception:
ORA-22905: cannot access rows from a non-nested table item
As I'd only ever done this when working with package, I previously worked around this by coding a function that returns the content of the relevent package variable. TABLE has no problem working out the datatype returned from a function.
It turns out I could have got away with just a simple CAST.
E.G. SELECT * FROM TABLE( CAST( table_variable AS table_type ) )
So, with that in mind, the first 'In Thing' example becomes this:
The Example:
In order to have something to access, we need the tables and data:
CREATE TABLE product
( id NUMBER
, descr VARCHAR2( 100 ) )
/
INSERT INTO product ( id, descr ) VALUES ( 1, 'one' );
INSERT INTO product ( id, descr ) VALUES ( 2, 'two' );
INSERT INTO product ( id, descr ) VALUES ( 3, 'three' );
INSERT INTO product ( id, descr ) VALUES ( 4, 'four' );
INSERT INTO product ( id, descr ) VALUES ( 5, 'five' );
INSERT INTO product ( id, descr ) VALUES ( 6, 'six' );
COMMIT;
In order to perform the cast we need to declare a type for the row in the table, and then the table type itself:
CREATE TYPE gt_id_type AS OBJECT ( id NUMBER )
/
CREATE TYPE gt_id_list_type AS TABLE OF gt_id_type
/
Then we define the package that will perform the cast.
We have the following functions
- GET_PRODUCTS, which is passed a table of IDs, and returns a ref cursor containing the products requested.
- GET_PRODS_BY_NAME, which is passed a string, and returns all the products that have a description containing that string. This function uses GET_PRODUCTS to return the product details
CREATE OR REPLACE PACKAGE product_pkg AS
TYPE gt_product_cur IS REF CURSOR;
FUNCTION get_products ( pt_id_list gt_id_list_type )
RETURN gt_product_cur;
FUNCTION get_prods_by_name ( pc_product_name VARCHAR2 )
RETURN gt_product_cur;
END;
/
CREATE OR REPLACE PACKAGE BODY product_pkg AS
--
gt_id_list gt_id_list_type;
--
FUNCTION get_products
( pt_id_list gt_id_list_type )
RETURN gt_product_cur IS
--
vt_product_cur gt_product_cur;
--
BEGIN
--
gt_id_list := pt_id_list;
--
OPEN vt_product_cur FOR
SELECT *
FROM product
WHERE id IN ( SELECT id
FROM TABLE( CAST( gt_id_list AS gt_id_list_type ) ) );
--
RETURN vt_product_cur;
--
END;
--
FUNCTION get_prods_by_name
( pc_product_name VARCHAR2 )
RETURN gt_product_cur IS
--
vt_product_ids gt_id_list_type;
--
BEGIN
--
SELECT gt_id_type( id )
BULK COLLECT
INTO vt_product_ids
FROM product
WHERE descr LIKE '%'|| pc_product_name|| '%';
--
RETURN get_products( vt_product_ids );
--
END;
--
END;
/
Finally, we have some code to run the GET_PRODS_BY_NAME function and return its set of values.
SET SERVEROUTPUT ON SIZE 1000000
DECLARE
--
vt_cur product_pkg.gt_product_cur;
vr_product_rec product%ROWTYPE;
--
BEGIN
--
vt_cur := product_pkg.get_prods_by_name( 't' );
--
LOOP
--
FETCH vt_cur INTO vr_product_rec;
EXIT WHEN vt_cur%NOTFOUND;
DBMS_OUTPUT.PUT_LINE( vr_product_rec.descr );
--
END LOOP;
--
END;
/
And the output:
two
three
Disclaimer: I've not yet managed to test this out with access from a PHP layer...
Technorati Tags: Robert+Baillie, oracle, table, cast, software+development, software, database, 9i, Amis
Friday, September 23, 2005
Friday afternoon...
Friday afternoons always seem to lead to pointless conversations, which sometimes lead to classic moments of comedy...
During an E-mail conversation about being vegetarian:
"In fact humans aren't carnivores at all. We meat eaters are technically eating carrion, which is meat that is dead for several days or weeks. That's why they hang cows and stuff up to enhance their flavour. We eat carrion, I.E. like vultures and hyeenas. This means we shouldn't kill at all, just eat what we find. I just happen to find it in the supermarket. It's not my fault there's a load of people who go around murdering animals and leave them in shops for me!"
During an E-mail conversation about being vegetarian:
"In fact humans aren't carnivores at all. We meat eaters are technically eating carrion, which is meat that is dead for several days or weeks. That's why they hang cows and stuff up to enhance their flavour. We eat carrion, I.E. like vultures and hyeenas. This means we shouldn't kill at all, just eat what we find. I just happen to find it in the supermarket. It's not my fault there's a load of people who go around murdering animals and leave them in shops for me!"
Monday, September 19, 2005
Google maps? PAH!
Ever since Google released the API for Google Maps it seems the whole of the internet has gone crazy for it. Cool things have appeared like an index of the current BBC news stories on a map of the UK. Add to that the fact that Google Earth is pretty tasty too and you'd be forgiven for thinking that no other mapping tools existed.
But... there is, and one of them does something cool and useful that Google Maps doesn't.
I run. Not much, but enough to manage a 10km run without passing out. And when I train I like to make sure that I know exactly how far I'm travelling. I like to plan my training schedule so I know that on Monday I'll do 5km, on Wednesday I'll do 2km fast + 1km jog + 2km fast + 1km jog. I know, I know, I can't help it.
Anyway. Google Maps doesn't help me there. But Map 24...
Map 24 has a really handy little ruler tool. Point and click a rubber band round the route you run and BOSH, the distance travelled rounded to the nearest 100th of a mile (or thereabouts). Very nice for working out 1km / 3km / 5km laps round your local streets.
Oh, and it does a really cool wooshy zoom thing when you put an address in!
Technorati Tags: Google, Google+maps, Google+earth, Map+24, Robert+Baillie
But... there is, and one of them does something cool and useful that Google Maps doesn't.
I run. Not much, but enough to manage a 10km run without passing out. And when I train I like to make sure that I know exactly how far I'm travelling. I like to plan my training schedule so I know that on Monday I'll do 5km, on Wednesday I'll do 2km fast + 1km jog + 2km fast + 1km jog. I know, I know, I can't help it.
Anyway. Google Maps doesn't help me there. But Map 24...
Map 24 has a really handy little ruler tool. Point and click a rubber band round the route you run and BOSH, the distance travelled rounded to the nearest 100th of a mile (or thereabouts). Very nice for working out 1km / 3km / 5km laps round your local streets.
Oh, and it does a really cool wooshy zoom thing when you put an address in!
Technorati Tags: Google, Google+maps, Google+earth, Map+24, Robert+Baillie
Friday, September 16, 2005
Feeling Smug
We've just gone live with a 40 user pilot of the latest version of the product we're developing, and once again I've been reminded why we work in an extreme programming kind of way, and why sometimes I just plain love this job!
Feedback, from the coal face...
And my personal favourite:
Technorati Tags: extreme+programming, XP, agile, Robert+Baillie, software, development, rollout
Feedback, from the coal face...
- "This is really, really good. You've done a great job."
- "It's very straightforward, isn't it?"
- "I'm loving this! You can tell that a lot of thought has gone into this"
And my personal favourite:
- "I thought I was going to hate it - but I love it!"
Technorati Tags: extreme+programming, XP, agile, Robert+Baillie, software, development, rollout
Thursday, September 15, 2005
Ch-ch-ch-ch-Chaaaanges
Well, after a couple of weeks of fiddling with HTML and CSS I've finally managed to replace the blog's bog standard Blogger template with a home grown one...
It may not be perfect, but at least it's mine!
Comments are more than welcome.
It may not be perfect, but at least it's mine!
Comments are more than welcome.
Sunday, September 11, 2005
Easy RSS syndication with FeedDigest
Thanks to a heads up from Andrew Beacock, I've taken a bit of a look at FeedDigest.
It's a very simple syndication site that allows you to easily put together RSS feeds and then produce HTML versions of them for placing on your site.
I can see how this sort of tool can really start to push the use of RSS. For me all it's meant that Bobablog now has the last 5 OraBlogs posts and the last 3 BobaPhotoBlog posts. But there's no reason why it should stop there.
You could put up a feed of your del.icio.us bookmarks, the latest news from the BBC, a central collection of your task lists from BackPack, or (using the search facility) a short list of your own posts on a particular topic.
The reason I think this is cool isn't because it does anything new... it doesn't. The reason is that it does things in a way that means that non developers can do it.
Technorati Tags: feed, digest, feeddigest, rss, syndication, feed+digest, Andrew+Beacock, Robert+Baillie
It's a very simple syndication site that allows you to easily put together RSS feeds and then produce HTML versions of them for placing on your site.
I can see how this sort of tool can really start to push the use of RSS. For me all it's meant that Bobablog now has the last 5 OraBlogs posts and the last 3 BobaPhotoBlog posts. But there's no reason why it should stop there.
You could put up a feed of your del.icio.us bookmarks, the latest news from the BBC, a central collection of your task lists from BackPack, or (using the search facility) a short list of your own posts on a particular topic.
The reason I think this is cool isn't because it does anything new... it doesn't. The reason is that it does things in a way that means that non developers can do it.
Technorati Tags: feed, digest, feeddigest, rss, syndication, feed+digest, Andrew+Beacock, Robert+Baillie
Saturday, September 10, 2005
Database Patch Runner: Design by Contract
So let's say that you've managed to put together a build script that will install the latest version of your database with the minimum of work and you've got your developers using the build to upgrade their own workspaces.
How can you push the patch runner? Actually test the upgrade and get easy to analyse information back from a nightly or continuous integration build? How can you protect your live databases and ensure that patches are only ever applied to databases when those databases are in the right state to receive those patches?
Bertrand Meyer developed the concept of Design by Contract. He suggested a technique whereby for each method there will be a contract, stated in terms of:
Our patch runner works in a similar way. Whenever a patch is written, pre and postcondition scripts are written. The precondition script embodies the assumptions about / requirements for the state of the
database immediately before the patch runs. The postconditions state the shape the database should be in once the patch has completed.
Immediately before running a given patch the patch runner will run the corresponding precondition script. The patch will not then be run unless the precondition script both exists and runs to completion. Only if and when the precondition script runs and reports no errors will the patch be applied.
Once the patch is complete the postcondition script is executed. If the postcondition script is missing, or reports a failure, then the build stops and the error is clearly reported.
Only when the pre, patch and post scripts have completed is the patch log updated to state that the patch has been applied. If any point of the process reports an error then the patch log is updated to state that the patch failed, and for what reason.
For the majority of patches, the pre and postconditions are fairly trivial, and can appear to be overkill. For example, if you're adding an unpopulated column to a table then the precondition is that the column does not exist, the postcondition is that it does.
The real advantage comes when you write data migrations. For example, a patch is needed that will move column X from table A to table B. A requirement may be that every value that was in B must exist in at least one column in table A, that no data is lost during the migration.
A precondition could be that there is at least one destination row in table A for each value. By checking this condition before the patch starts we can stop the patch from destroying data.
Another example may be the reforming of some tables that contain monetary values. It may be required that whilst data is being moved between rows or columns, that the sum total of all values in a particular set of columns be the same on completion of the patch as it was at the start. The precondition script can store the original sum totals, the postcondition can then check the resulting totals after the patch is complete.
Producing the pre and postcondition scripts focus the developer on two things:
We've found that using this structure greatly increases the feedback we get from our builds.
If you can get your DBA to buy into the idea, you can produce an overnight test build using the most recent backup from your live system. Overnight, automatically copy live, upgrade it and have your build produce a report on the success of the current build against the current candidate for upgrade. This report will warn you if the data in the live system is moving away from the assumptions you originally had when producing your patches. It is much easier to deal with such issues when you find out during your development cycle, rather than during or, even worse, days after the upgrade has been applied to the production environment. An upgrade patch becomes a very reliable thing when it's been ran 50 times against 50 different sets of data, each time reporting its success of failure.
In addition, the postcondition scripts act as clear documentation as to the aim of the patch. This is of great use if and when you find a performance problem with a particular patch. Rewriting a patch 2 months after it was first put together is so much easier when you have a postcondition script to act as both documentation and sanity check.
As a possible variation, on finding failures it should be possible for the patch runner to automatically rollback the failed change, taking the database back to the state immediately before the patch started. In some environments this may be critical, however we've not yet found a pressing need and therefore in our version we do not automatically rollback failures.
Of course, the mechanism is only as good as the pre and postcondition scripts that are produced, but then you ensure quality by always pair programming don't you ;-)
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch, DbC, Design+by+Contract, db, dbms
How can you push the patch runner? Actually test the upgrade and get easy to analyse information back from a nightly or continuous integration build? How can you protect your live databases and ensure that patches are only ever applied to databases when those databases are in the right state to receive those patches?
Bertrand Meyer developed the concept of Design by Contract. He suggested a technique whereby for each method there will be a contract, stated in terms of:
- Preconditions: These conditions should be true before the function executes.
- Postconditions: Given the preconditions are upheld, the function guarantees that on completion the postconditions will be true.
Our patch runner works in a similar way. Whenever a patch is written, pre and postcondition scripts are written. The precondition script embodies the assumptions about / requirements for the state of the
database immediately before the patch runs. The postconditions state the shape the database should be in once the patch has completed.
Immediately before running a given patch the patch runner will run the corresponding precondition script. The patch will not then be run unless the precondition script both exists and runs to completion. Only if and when the precondition script runs and reports no errors will the patch be applied.
Once the patch is complete the postcondition script is executed. If the postcondition script is missing, or reports a failure, then the build stops and the error is clearly reported.
Only when the pre, patch and post scripts have completed is the patch log updated to state that the patch has been applied. If any point of the process reports an error then the patch log is updated to state that the patch failed, and for what reason.
For the majority of patches, the pre and postconditions are fairly trivial, and can appear to be overkill. For example, if you're adding an unpopulated column to a table then the precondition is that the column does not exist, the postcondition is that it does.
The real advantage comes when you write data migrations. For example, a patch is needed that will move column X from table A to table B. A requirement may be that every value that was in B must exist in at least one column in table A, that no data is lost during the migration.
A precondition could be that there is at least one destination row in table A for each value. By checking this condition before the patch starts we can stop the patch from destroying data.
Another example may be the reforming of some tables that contain monetary values. It may be required that whilst data is being moved between rows or columns, that the sum total of all values in a particular set of columns be the same on completion of the patch as it was at the start. The precondition script can store the original sum totals, the postcondition can then check the resulting totals after the patch is complete.
Producing the pre and postcondition scripts focus the developer on two things:
- What assumptions am I making about the structure of the data I am about to transform, and which of those assumptions are critical to my patch's success?
- How can I measure the success of my patch, and what requirements do I have of the resulting data?
We've found that using this structure greatly increases the feedback we get from our builds.
If you can get your DBA to buy into the idea, you can produce an overnight test build using the most recent backup from your live system. Overnight, automatically copy live, upgrade it and have your build produce a report on the success of the current build against the current candidate for upgrade. This report will warn you if the data in the live system is moving away from the assumptions you originally had when producing your patches. It is much easier to deal with such issues when you find out during your development cycle, rather than during or, even worse, days after the upgrade has been applied to the production environment. An upgrade patch becomes a very reliable thing when it's been ran 50 times against 50 different sets of data, each time reporting its success of failure.
In addition, the postcondition scripts act as clear documentation as to the aim of the patch. This is of great use if and when you find a performance problem with a particular patch. Rewriting a patch 2 months after it was first put together is so much easier when you have a postcondition script to act as both documentation and sanity check.
As a possible variation, on finding failures it should be possible for the patch runner to automatically rollback the failed change, taking the database back to the state immediately before the patch started. In some environments this may be critical, however we've not yet found a pressing need and therefore in our version we do not automatically rollback failures.
Of course, the mechanism is only as good as the pre and postcondition scripts that are produced, but then you ensure quality by always pair programming don't you ;-)
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch, DbC, Design+by+Contract, db, dbms
Wednesday, September 07, 2005
The Database Patch Runner: Dealing with code
Previously I've talked about the database patch runner as a way of easily and consistently getting database changes into version control, onto databases and under automated frameworks. But one topic I think I glossed over was: Which database objects fall under the patch runner, and how do you deal with those that don't.
A big advantage of the patch runner is that it groups functional changes together and will ensure that those changes are applied to a given database once and only once. A disadvantage is that it removes the object centric view of changes from version control and puts it into the database. For tables, I really don't see this as a problem. For packages, procedure and functions this is simply unacceptable; we need to keep source code grouped in the more traditional object centric manner.
We could have developers make their changes to the individual procedures and suchlike and then get them to add the source code to the patches one they've finished. But they'd probably forget a file every now and again, and would moan about the task. We could have a build manager monitor the version control repository and generate the list of source code files that are needed for the jump between any two given tagged versions of the system and build patch files upon request. But that would mean that we would need to employ a build manager to do this job.
Ideally we want a solution that will minimise the overall work in managing the build script, not just the work for the developer.
One of the reasons why we use the patch runner is to ensure that destructive code, or code that changes the underlying structure of a database cannot be run more that once. The implication of this is that statements which can be ran multiple times without destroying structure or content, due to their intrinsic nature, do not need to form part of the patch runner.
That is, if a procedure was to be dropped and re-created, the only impact would be to temporarily invalidate any other procedures calling that procedure. Oracle can deal with this and can be set to re-compile dependencies when a procedure is called. The overall structure and content of the database is not changed by re-creating a procedure. The intrinsic nature of the procedure means that it can be re-installed without damaging the database.
This is not so when dealing with tables. If a table was to be dropped and re-created*, the impact would be to loose the data previously held in that table. The result of re-creating a table that has not changed is that the overall structure will remain the same, but the content will not.
This difference is crucial in understanding which objects need to fall under the control of the patch runner and which objects do not, as well as understanding how we can then deal with the objects that do not.
Of course, there is nothing stopping you from putting any particular set of objects under the control of the patch runner if you feel it is appropriate. For example, indexes can be dropped and re-created without any risk of loss of content and so you may regard these as outside the patch runner's concerns. However, indexes on large tables can take time to create and most of the data migrations that take place in the patch runner scripts would benefit from those indexes. For these reasons it may sometimes be appropriate to put the indexes into patch scripts.
For us, the split between patch runner and non patch runner is as such:
Patch Runner:
Non Patch Runner:
The list isn't exhaustive by any means; it covers the objects we use. As any new object type comes into focus we get together to decide if it should be installed by the patch runner.
So, knowing which objects do not fall into the realm of the patch runner, we then need to actually deal with those objects.
As stated above, the primary factor for deciding when an object should fall under outside of the patch runner's remit is if that object can be freely replaced with a new version of that object with no further work. We use that to our advantage, and state that since all objects outside of the patch runner can be replaced when they have changed, then all objects outside of the patch runner will be replaced irrespective of whether that object has changed or not.
That is, our patch runner sits within a larger build script. In our case this build script is a master batch file and a collection of SQL scripts, though I see no reason why this shouldn't be Unix scripts, ANT tasks, or whatever. The overarching build scripts contain sections that will install objects that are required before the patch runner can execute, and others that require the patch runner to have completed its task before they are installed. In every case, each of these scripts install all objects required by the database, not caring if they previously existed in the correct form.
In some cases a single script will create the full set of a single object type; all grants are created in a single script, as are synonyms. In other cases a single script will exist for each individual object; each package specification has a script to itself, separated from its corresponding package body. In adding a new object to the database schema, the developer needs to add that object to the relevant controlling build script.
This setup allows us to separately manage the version control for each individual object where that object is sufficiently important, whilst managing the number of scripts that exist for the less verbose creation statements.
By ensuring that all objects are created during every build sequence we simplify two processes:
The result is that whilst the objects fall within a highly structured build script, the developer need not think about it except when adding new objects. The PL/SQL source code can be managed like any other source code, each component falling under version control as an individual component.
We acknowledge that the build script could be better, and that the controlling install scripts could be generated (run all files from directory x, or run all files with extension '.xxx'), though in reality the maintenance of this script is minimal (a single number of minutes each week). Also, putting this in place would have an impact only on the build script, not on the individual object create scripts.
Additionally, it can appear to be overkill to install the full set of source code on each build, even small patch releases. However, installing source code onto an Oracle database is generally pretty fast. We find that the build script spends far more time running data migrations than installing code.
We exclusively use packages (no standalone procedures, functions or triggers), and so our build scripts are simple: We can install all the package specifications, then all the package bodies and can be sure that they will compile; dependencies do not affect the order of installation.
Views are installed in an order dictated by dependencies, though this does not prove difficult. If it did I'm sure we could 'force create' them.
Simplicity aside, I'm certain that even if we had difficult interdependencies with a very large number of objects, we would first test the ability to manage their creation in this way.
In short, I acknowledge that for larger projects there may be difficulties with the approach in the simplest form, but I'm more than confident that the basic theory holds. If not, I'd like to hear why, since our small (ish) project will inevitably become a very large one, as is the way with database applications.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch
A big advantage of the patch runner is that it groups functional changes together and will ensure that those changes are applied to a given database once and only once. A disadvantage is that it removes the object centric view of changes from version control and puts it into the database. For tables, I really don't see this as a problem. For packages, procedure and functions this is simply unacceptable; we need to keep source code grouped in the more traditional object centric manner.
We could have developers make their changes to the individual procedures and suchlike and then get them to add the source code to the patches one they've finished. But they'd probably forget a file every now and again, and would moan about the task. We could have a build manager monitor the version control repository and generate the list of source code files that are needed for the jump between any two given tagged versions of the system and build patch files upon request. But that would mean that we would need to employ a build manager to do this job.
Ideally we want a solution that will minimise the overall work in managing the build script, not just the work for the developer.
One of the reasons why we use the patch runner is to ensure that destructive code, or code that changes the underlying structure of a database cannot be run more that once. The implication of this is that statements which can be ran multiple times without destroying structure or content, due to their intrinsic nature, do not need to form part of the patch runner.
That is, if a procedure was to be dropped and re-created, the only impact would be to temporarily invalidate any other procedures calling that procedure. Oracle can deal with this and can be set to re-compile dependencies when a procedure is called. The overall structure and content of the database is not changed by re-creating a procedure. The intrinsic nature of the procedure means that it can be re-installed without damaging the database.
This is not so when dealing with tables. If a table was to be dropped and re-created*, the impact would be to loose the data previously held in that table. The result of re-creating a table that has not changed is that the overall structure will remain the same, but the content will not.
* Re-creating a table here being: dropping the table, cascading the drop of any keys on / to that table, and re-creating both the table and those keys.
This is not a small amount of work in itself, and if this was not done, the structure would also change.
This is not a small amount of work in itself, and if this was not done, the structure would also change.
This difference is crucial in understanding which objects need to fall under the control of the patch runner and which objects do not, as well as understanding how we can then deal with the objects that do not.
Of course, there is nothing stopping you from putting any particular set of objects under the control of the patch runner if you feel it is appropriate. For example, indexes can be dropped and re-created without any risk of loss of content and so you may regard these as outside the patch runner's concerns. However, indexes on large tables can take time to create and most of the data migrations that take place in the patch runner scripts would benefit from those indexes. For these reasons it may sometimes be appropriate to put the indexes into patch scripts.
For us, the split between patch runner and non patch runner is as such:
Patch Runner:
- Tables
- Indexes
- Materialized Views
Non Patch Runner:
- Grants / Synonyms
- Views
- Packages / Functions / Procedures
The list isn't exhaustive by any means; it covers the objects we use. As any new object type comes into focus we get together to decide if it should be installed by the patch runner.
So, knowing which objects do not fall into the realm of the patch runner, we then need to actually deal with those objects.
As stated above, the primary factor for deciding when an object should fall under outside of the patch runner's remit is if that object can be freely replaced with a new version of that object with no further work. We use that to our advantage, and state that since all objects outside of the patch runner can be replaced when they have changed, then all objects outside of the patch runner will be replaced irrespective of whether that object has changed or not.
That is, our patch runner sits within a larger build script. In our case this build script is a master batch file and a collection of SQL scripts, though I see no reason why this shouldn't be Unix scripts, ANT tasks, or whatever. The overarching build scripts contain sections that will install objects that are required before the patch runner can execute, and others that require the patch runner to have completed its task before they are installed. In every case, each of these scripts install all objects required by the database, not caring if they previously existed in the correct form.
In some cases a single script will create the full set of a single object type; all grants are created in a single script, as are synonyms. In other cases a single script will exist for each individual object; each package specification has a script to itself, separated from its corresponding package body. In adding a new object to the database schema, the developer needs to add that object to the relevant controlling build script.
This setup allows us to separately manage the version control for each individual object where that object is sufficiently important, whilst managing the number of scripts that exist for the less verbose creation statements.
By ensuring that all objects are created during every build sequence we simplify two processes:
- Implementing a change in a given object requires only that the create script is edited, therefore minimising the work a developer must do to implement that change.
- Building the release does not require knowledge of the source version, only the target version, therefore minimising the work required in generating a release.
The result is that whilst the objects fall within a highly structured build script, the developer need not think about it except when adding new objects. The PL/SQL source code can be managed like any other source code, each component falling under version control as an individual component.
We acknowledge that the build script could be better, and that the controlling install scripts could be generated (run all files from directory x, or run all files with extension '.xxx'), though in reality the maintenance of this script is minimal (a single number of minutes each week). Also, putting this in place would have an impact only on the build script, not on the individual object create scripts.
Additionally, it can appear to be overkill to install the full set of source code on each build, even small patch releases. However, installing source code onto an Oracle database is generally pretty fast. We find that the build script spends far more time running data migrations than installing code.
We exclusively use packages (no standalone procedures, functions or triggers), and so our build scripts are simple: We can install all the package specifications, then all the package bodies and can be sure that they will compile; dependencies do not affect the order of installation.
Views are installed in an order dictated by dependencies, though this does not prove difficult. If it did I'm sure we could 'force create' them.
Simplicity aside, I'm certain that even if we had difficult interdependencies with a very large number of objects, we would first test the ability to manage their creation in this way.
In short, I acknowledge that for larger projects there may be difficulties with the approach in the simplest form, but I'm more than confident that the basic theory holds. If not, I'd like to hear why, since our small (ish) project will inevitably become a very large one, as is the way with database applications.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch
Friday, September 02, 2005
A little more conversation
In my usual style, I'm finding it difficult to walk away from a conversation on Wilfred van der Deijl's blog, this time with a guy called Chuck.
His comment can be found here, with my reply following close behind.
I wouldn't normally link to a comment like this, but I feel the message I'm trying to get across with the Patch Runner is well illustrated by my confusions about Chuck's company's approach.
As he clearly points out, the CMM level 3 accreditation states that the process is repeatable, but not necessarily appropriate.
Technorati Tags: Oracle, patch, upgrade, software, development, CMM, Robert+Baillie, Wilfred+van+der+Deijl
His comment can be found here, with my reply following close behind.
I wouldn't normally link to a comment like this, but I feel the message I'm trying to get across with the Patch Runner is well illustrated by my confusions about Chuck's company's approach.
As he clearly points out, the CMM level 3 accreditation states that the process is repeatable, but not necessarily appropriate.
Technorati Tags: Oracle, patch, upgrade, software, development, CMM, Robert+Baillie, Wilfred+van+der+Deijl
WTF
For a while now I've been reading the consistently amusing Daily WTF. Well now, thanks to William Robertson, James Padfield, Thai Rices and Adrian Billington we have the Oracle WTF. It's started well...
Technorati Tags: Oracle, WTF, software, development, internet,
Technorati Tags: Oracle, WTF, software, development, internet,
Tuesday, August 16, 2005
Database Upgrade Scripts – Why all the effort?
On Wilfred van der Deijl's blog, Chuck (amongst other things) effectively asks:
"How much effort do you dedicate to total automation when you still need someone smart enough to [deal with failures]".
In order to address this I think I first want to address the question, what are we trying to do with automation.
The aim of is to make it easy to re-run the upgrade with as little effort as possible, with as many configruations as possible, thus testing the upgrade as much as possible and hopefully making the upgrade solid and reliable. Of course we can't make sure that the upgrade works every time with every configuration of data, but we can make sure it runs successfully a lot more often than it doesn't.
This gives us confidence in our ability to change the databases, and in doing so makes us more likely to re-work difficult data structures rather than work around them. This means that our database is better to work with, which makes our jobs easier.
Also, whenever we make a problem free roll-out we increase the confidence the rest of the business has in our ability to do our job. It makes them more open to receiving more upgrades more often and makes them easier to roll them out when we do. This means our customers get their bug fies earlier and their enhancements earlier, and can therefore give us feedback on where to make more enhancements earlier in the software's lifespan.
In short, making the upgrades solid helps us write better software by allowing us to focus on the software rather than the software roll-out, and the customer on the possibilities of new software rather than software failure..
How does automation give us this? Well, the ability to automate builds does not, it's the way in which those automated builds are used that does: Why not make it possible for an overnight process to perform the upgrade to as many different production databases as you can gather the resources to do?
In putting together an automated build plan we want builds on test databases that occur every night, using recent (that day's?) backups of production systems. We want to be able to run through the upgrade as it would occur on live as many times as possible, and we want to do that without draining our resources to the point that it's all we are doing.
If we can have unattended backups of our live system, unattended rebuilds of that live system on a test server, unattended upgrading of that database and then unattended testing of the resultant application, then we can eaily test the upgrade of the live system from the moment the project starts to the night before the production upgrade takes place.
If we do this, then the odds are that by the time we decide to upgrade the production system we know about that last minute data problem that will cause the build to fail. We'll have fixed the problem before the upgrade started, and we'll have dealt with in when we're not in a panic, we'll have done all this without teams of users waiting for the production database to come back up.
Our aim is not to have a completely unskilled worker to perform the task of upgrading the production database, but to make sure the upgrade will go smoothly far more often than not. We want that standby DBA to stay on standby.
That seems like worth a bit of effort to me!
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, Wilfred+van+der+Deijl, patch
"How much effort do you dedicate to total automation when you still need someone smart enough to [deal with failures]".
In order to address this I think I first want to address the question, what are we trying to do with automation.
The aim of is to make it easy to re-run the upgrade with as little effort as possible, with as many configruations as possible, thus testing the upgrade as much as possible and hopefully making the upgrade solid and reliable. Of course we can't make sure that the upgrade works every time with every configuration of data, but we can make sure it runs successfully a lot more often than it doesn't.
This gives us confidence in our ability to change the databases, and in doing so makes us more likely to re-work difficult data structures rather than work around them. This means that our database is better to work with, which makes our jobs easier.
Also, whenever we make a problem free roll-out we increase the confidence the rest of the business has in our ability to do our job. It makes them more open to receiving more upgrades more often and makes them easier to roll them out when we do. This means our customers get their bug fies earlier and their enhancements earlier, and can therefore give us feedback on where to make more enhancements earlier in the software's lifespan.
In short, making the upgrades solid helps us write better software by allowing us to focus on the software rather than the software roll-out, and the customer on the possibilities of new software rather than software failure..
How does automation give us this? Well, the ability to automate builds does not, it's the way in which those automated builds are used that does: Why not make it possible for an overnight process to perform the upgrade to as many different production databases as you can gather the resources to do?
In putting together an automated build plan we want builds on test databases that occur every night, using recent (that day's?) backups of production systems. We want to be able to run through the upgrade as it would occur on live as many times as possible, and we want to do that without draining our resources to the point that it's all we are doing.
If we can have unattended backups of our live system, unattended rebuilds of that live system on a test server, unattended upgrading of that database and then unattended testing of the resultant application, then we can eaily test the upgrade of the live system from the moment the project starts to the night before the production upgrade takes place.
If we do this, then the odds are that by the time we decide to upgrade the production system we know about that last minute data problem that will cause the build to fail. We'll have fixed the problem before the upgrade started, and we'll have dealt with in when we're not in a panic, we'll have done all this without teams of users waiting for the production database to come back up.
Our aim is not to have a completely unskilled worker to perform the task of upgrading the production database, but to make sure the upgrade will go smoothly far more often than not. We want that standby DBA to stay on standby.
That seems like worth a bit of effort to me!
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, Wilfred+van+der+Deijl, patch
Friday, August 12, 2005
A seminal essay and a difference of opinion
Thanks to Wilfred van der Deijl's post here, I've just read a January 2003 article by Martin Fowler and Pramod Sadalage... and I can't believe that I had previously missed it!
Martin and Pramod very clearly discuss the overarching issues that appear once you start to look at database development in an agile manner, and you can very easily see from their discussion how important a clear and solid patch runner structure is to successful agile database development.
Not long after this article was written we were just starting to think about the same practices and many of the conclusions we came to matched. Not least the need to implement sandbox databases for each workspace and the need for consistent test data across those databases.
However, our conclusions did differ in one fundamental way, and I find it difficult to understand Martin and Pramod's (M&P) approach in this particular area.
My issue relates directly to the propagation of database changes across the development team. In M&P's approach, database changes are automatically applied to the development workspaces as they occur, managed by the team's DBA. They point out that:
'people are usually concerned that automatically updating developers databases underneath them will cause a problem, but we found that it worked just fine'
I am one of those concerned people. I am concerned in the same way that I would be if I was told that the source code I was working with would be automatically updated at regular intervals as changes occurred. Let me rephrase the above statement with that in mind:
'people are usually concerned that automatically updating developers source code underneath them will cause a problem, but we found that it worked just fine'
Suddenly the statement does not seem quite so reasonable!
In order to develop I need to clearly understand what is within my control and what is outside of my control. I need to be able to rely on the known state of my own workspace. For me, this is a founding principle behind the idea of the development workspace as a sandbox.
A given version of an application is developed to run against a given version of the database. Because of this, the database is as much a part of the workspace as the rest of the source code.
There is also the issue of the database change being applied in advance of the related code change being checked into the version control system, and the manual process therefore required. In M&P's process they will notify the DBA of the changes required once they are decided upon. At some point in the near future the DBA will then make the changes to the central databases and the changes will propagate to the development workspaces. As this happens there are three clear risks that I can see:
1.The database schema change is made a significant amount of time before or after the associated code change is committed to version control.
2.The change required by the developer is miscommunicated to the DBA and an incorrect change is applied.
3.The change is mistakenly applied to development databases that are following a different branch to that in which the change is made.
In all the above cases, the effective result is that the change may invalidate a particular component of the application due to the development (or integration) database being out of step with the source code being ran against that database.
I believe all this risks can be mitigated against by making the following changes to the described process:
1.Make the developers responsible for producing the actual patches that will be eventually be ran against all databases, development, through integration to live. These patches should form part of an clear structured patch runner, and should be placed in version control alongside the rest of the application source code.
2.Make each developer responsible for the maintenance of their own database workspace. Make it easy for a developer to upgrade their database, and make them do so using those scripts that will be ran against all other instances of the database. Make it part of the routine that immediately after updating their source code workspace they upgrade their database.
3.Put the database upgrade into the automated build / continuous integration test suite and ensure that the build being performed by the automated build is exactly the same as that which would be ran on the live system.
These practices have the added advantage of minimising the amount of work required by the DBA, who can exist in a more advisory role within the team.
Of course, there are times where data migrations will take a non trivial amount of time to complete. In these cases it is important that developers are warned of the fact and are able to schedule times when these changes take place so as to minimise the impact on their work.
Having said this, agile database development is a new venture for most everybody involved, and work such as this should not be underestimated, and cannot understated. There will likely be many different ideas on this topic, coming from many different people, and it's a pleasure to be involved. It is very easy to forget just how much database development has evolved in the last 10 years!
Technorati Tags: Oracle, agile, extreme+programming, software, development, Robert+Baillie, upgrade, database, Martin+Fowler, Pramod+Sadalage
Martin and Pramod very clearly discuss the overarching issues that appear once you start to look at database development in an agile manner, and you can very easily see from their discussion how important a clear and solid patch runner structure is to successful agile database development.
Not long after this article was written we were just starting to think about the same practices and many of the conclusions we came to matched. Not least the need to implement sandbox databases for each workspace and the need for consistent test data across those databases.
However, our conclusions did differ in one fundamental way, and I find it difficult to understand Martin and Pramod's (M&P) approach in this particular area.
My issue relates directly to the propagation of database changes across the development team. In M&P's approach, database changes are automatically applied to the development workspaces as they occur, managed by the team's DBA. They point out that:
'people are usually concerned that automatically updating developers databases underneath them will cause a problem, but we found that it worked just fine'
I am one of those concerned people. I am concerned in the same way that I would be if I was told that the source code I was working with would be automatically updated at regular intervals as changes occurred. Let me rephrase the above statement with that in mind:
'people are usually concerned that automatically updating developers source code underneath them will cause a problem, but we found that it worked just fine'
Suddenly the statement does not seem quite so reasonable!
In order to develop I need to clearly understand what is within my control and what is outside of my control. I need to be able to rely on the known state of my own workspace. For me, this is a founding principle behind the idea of the development workspace as a sandbox.
A given version of an application is developed to run against a given version of the database. Because of this, the database is as much a part of the workspace as the rest of the source code.
There is also the issue of the database change being applied in advance of the related code change being checked into the version control system, and the manual process therefore required. In M&P's process they will notify the DBA of the changes required once they are decided upon. At some point in the near future the DBA will then make the changes to the central databases and the changes will propagate to the development workspaces. As this happens there are three clear risks that I can see:
1.The database schema change is made a significant amount of time before or after the associated code change is committed to version control.
2.The change required by the developer is miscommunicated to the DBA and an incorrect change is applied.
3.The change is mistakenly applied to development databases that are following a different branch to that in which the change is made.
In all the above cases, the effective result is that the change may invalidate a particular component of the application due to the development (or integration) database being out of step with the source code being ran against that database.
I believe all this risks can be mitigated against by making the following changes to the described process:
1.Make the developers responsible for producing the actual patches that will be eventually be ran against all databases, development, through integration to live. These patches should form part of an clear structured patch runner, and should be placed in version control alongside the rest of the application source code.
2.Make each developer responsible for the maintenance of their own database workspace. Make it easy for a developer to upgrade their database, and make them do so using those scripts that will be ran against all other instances of the database. Make it part of the routine that immediately after updating their source code workspace they upgrade their database.
3.Put the database upgrade into the automated build / continuous integration test suite and ensure that the build being performed by the automated build is exactly the same as that which would be ran on the live system.
These practices have the added advantage of minimising the amount of work required by the DBA, who can exist in a more advisory role within the team.
Of course, there are times where data migrations will take a non trivial amount of time to complete. In these cases it is important that developers are warned of the fact and are able to schedule times when these changes take place so as to minimise the impact on their work.
Having said this, agile database development is a new venture for most everybody involved, and work such as this should not be underestimated, and cannot understated. There will likely be many different ideas on this topic, coming from many different people, and it's a pleasure to be involved. It is very easy to forget just how much database development has evolved in the last 10 years!
Technorati Tags: Oracle, agile, extreme+programming, software, development, Robert+Baillie, upgrade, database, Martin+Fowler, Pramod+Sadalage
Wednesday, August 10, 2005
Named Notation Parameters in easy to read unit test shock!
One of the better kept secrets of Oracle is the ability to use 'named parameter passing' over 'positional parameter passing'. Oracle covers it here.
That is, if I want to call a procedure that has three parameters that have defaults, and I want to a value pass into the third parameter, I can do so by referencing the name of the third parameter….
Give the function definition:
Can be called by performing the following:
OK, so in the example given it may make a lot more sense to just order the parameters a little better, like have the employee name first, but you get the idea.
So, it looks cool, and you may be able to think of a few instances where it may prove useful. It can be handy if you think your procedure signatures are likely to change and you have an out parameter you want to keep to the end of the procedure definition...
It can be regarded as tidy make sure that error message parameter is at the bottom, but without having named parameter notation you would never get the benefit of the default parameters, and would have to change all your calls if you ever added a new field between the department and manager id.
Quite handy, but nothing really earth shattering.
The place where we’ve found the most use is in unit tests...
Lets say we’re writing a test for the function:
Lets say that this function has many different ways it can fail: Any of the parameters being NULL, the from data being later than the to date, the total number of days over the allocation...
In each case the function will fail in the same way. Fail to insert the holiday record, return FALSE and set pc_error_message to the reason why it failed.
In order to test for this conditions we write a simple failure check procedure with a signature along the lines of:
Each of the insert_holiday’s input parameters are duplicated on the check procedure, and set to be valid values for that procedure.
Check_insert_holiday_fails calls insert_holiday with the passed in values and goes on to check for the correct three error conditions: No increase in number of holiday records, returning false and passing back an error message.
The pc_context is appended to each of the assertion texts in order to give a nice readout. So, for example, the check false assertion may be (using UtPlsql):
The idea is that if the procedure was called with only the context value specifed, the call to the tested insert_holiday function would be successful (and the test would fail, if that makes sense!).
So, we have a single procedure that will check that a failure state is returned, covering all the components. We can then call this with our error states, using the named parameter notation in order to only change the parameters we are interested in changing. E.G.
The use of the named notation means that only the parameters important to the failure are stated, rather than the full list. This makes it easier to see each individual test case clearly. If the procedure being tested has a lot of parameters, then the advantage becomes very clear!
Technorati Tags: Oracle, unit+testing, extreme+programming, software, development, Robert+Baillie, test, testing
Update: Sorry for the chnage in permalink address. I just couldn't handle the typo in the title!
That is, if I want to call a procedure that has three parameters that have defaults, and I want to a value pass into the third parameter, I can do so by referencing the name of the third parameter….
Give the function definition:
FUNCTION insert_employee( pn_department_id NUMBER := NULL
, pn_manager_id NUMBER := NULL
, pc_employee_name VARCHAR2 ) RETURN NUMBER;
Can be called by performing the following:
vn_employee_id := insert_employee( pc_employee_name => 'Rob Baillie' );
OK, so in the example given it may make a lot more sense to just order the parameters a little better, like have the employee name first, but you get the idea.
So, it looks cool, and you may be able to think of a few instances where it may prove useful. It can be handy if you think your procedure signatures are likely to change and you have an out parameter you want to keep to the end of the procedure definition...
FUNCTION insert_employee( pc_employee_name IN VARCHAR2
, pn_department_id IN NUMBER := NULL
, pn_manager_id IN NUMBER := NULL
, pc_error_message OUT VARCHAR2 ) RETURN NUMBER;
It can be regarded as tidy make sure that error message parameter is at the bottom, but without having named parameter notation you would never get the benefit of the default parameters, and would have to change all your calls if you ever added a new field between the department and manager id.
Quite handy, but nothing really earth shattering.
The place where we’ve found the most use is in unit tests...
Lets say we’re writing a test for the function:
FUNCTION insert_holiday( pn_employee_id IN NUMBER
, pd_from_date IN DATE
, pd_to_date IN DATE
, pc_error_message OUT VARCHAR2 ) RETURN BOOLEAN;
Lets say that this function has many different ways it can fail: Any of the parameters being NULL, the from data being later than the to date, the total number of days over the allocation...
In each case the function will fail in the same way. Fail to insert the holiday record, return FALSE and set pc_error_message to the reason why it failed.
In order to test for this conditions we write a simple failure check procedure with a signature along the lines of:
PROCEDURE check_insert_holiday_fails( pc_context VARCHAR2
, pn_employee_id NUMBER := 7438
, pd_from_date DATE := TRUNC( SYSDATE ) + 10
, pd_to_date DATE := TRUNC( SYSDATE ) + 17 )
Each of the insert_holiday’s input parameters are duplicated on the check procedure, and set to be valid values for that procedure.
Check_insert_holiday_fails calls insert_holiday with the passed in values and goes on to check for the correct three error conditions: No increase in number of holiday records, returning false and passing back an error message.
The pc_context is appended to each of the assertion texts in order to give a nice readout. So, for example, the check false assertion may be (using UtPlsql):
utAssert.this( 'When ' || pc_context ||', insert_holiday returns false', NOT vb_result );
The idea is that if the procedure was called with only the context value specifed, the call to the tested insert_holiday function would be successful (and the test would fail, if that makes sense!).
So, we have a single procedure that will check that a failure state is returned, covering all the components. We can then call this with our error states, using the named parameter notation in order to only change the parameters we are interested in changing. E.G.
check_insert_holiday_fails( 'invalid employee_id' , pn_employee_id => -1 );
check_insert_holiday_fails( 'NULL employee_id' , pn_employee_id => NULL );
check_insert_holiday_fails( 'from date after to date', pd_from_date => SYSDATE + 5, pd_to_date => SYSDATE + 2 );
check_insert_holiday_fails( 'from date in past' , pd_from_date => SYSDATE - 1 );
check_insert_holiday_fails( 'to date in past' , pd_to_date => SYSDATE - 1 );
The use of the named notation means that only the parameters important to the failure are stated, rather than the full list. This makes it easier to see each individual test case clearly. If the procedure being tested has a lot of parameters, then the advantage becomes very clear!
Technorati Tags: Oracle, unit+testing, extreme+programming, software, development, Robert+Baillie, test, testing
Update: Sorry for the chnage in permalink address. I just couldn't handle the typo in the title!
Saturday, August 06, 2005
Haloscan Ping 0.3 (alpha 2) released
For those that are interested, a new version of Haloscan Ping has been released. Thanks go to Andrew Beacock and Ryan Cullen for their input!
This version fixes a couple of minor bugs with the first alpha...
What we're currently working on for the next version:
As with the previous version, if anyone wants it, please mail me!
Technorati Tags: Robert+Baillie,Andrew+Beacock,Ryan+Cullen Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
This version fixes a couple of minor bugs with the first alpha...
- Atom feeds with no content, but a summary tag are now recognised correctly
- NULL entries no longer cause the ping screen to crash
- If an entry is shorter than the minimum number of characters, it will still be chopped off to the nearest sentence
What we're currently working on for the next version:
- Ability to send multiple pings in a single submit
- Automatically stripping tags from the content
As with the previous version, if anyone wants it, please mail me!
Technorati Tags: Robert+Baillie,Andrew+Beacock,Ryan+Cullen Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
The Database Patch Runner: Table Centric Views
On Wilfred van der Deijl's blog we got into a nice discussion about grabbing a table centric history of the patches applied to a database when using a functional patch centric upgrade organisation.
I think I've made it obvious in the past that I massively favour the functional grouping, since I think it makes the job of the developer and the person performing the upgrade that much clearer. However, I acknowledge the perceived need for a table history, and started thinking about how you might produce it.
Just as I was getting to some sort of conclusion, Wilfred put together a couple of great ideas... and I thought I'd give them a critical review.
Forgive me for this Wilfred... I really wanted to get this down, I think it's a great topic!
Group the patches by table, then add interpreted comments to the files in order to state which patch a given ALTER TABLE statement belongs with
I'm not sure about this solution for a simple reason. I don't like organising the source files by tables; I think this makes the developer's job that much harder.
In producing a patch the developer needs to update several files and cannot easily see the order in which these changes are applied.
I simple situation where this becomes very important is where a column needs to be moved from one table to another. In order to do so, I cannot see how this can be done without changing at least two files; one that adds the new column, and one that drops the old.. In addition, you need to find somewhere to put the data migration script. Does this go into to the DDL file for the table having the column added? Or do you could add a third file into the mix.
I have found in the past that the create column and data migration get put into the table scripts and there is a manual process added to ensure that the existing column gets dropped. The process is then forgotten in the heat of the production upgrade and the redundant column remains in the schema.
In addition, with the table centric grouping it is easy for a developer to miss a step in the DDL, a column isn't added to a table, for example. By having the functional grouping it's easier to spot this mistake since the developer has a single file that lists all the DDL applicable for that functional change.
Finally, there is a need to add that extra step... adding the comments to the table create scripts. I have an objection to this in the same way that I have an objection to JavaDoc comments. People simply don't add them, and nobody notices / cares until such time as those missing comments are crucial. By then it's too late. The comments could be policed, but whenever I see something that needs policing I see something that needs changing so the policing is no longer needed.
Another way would be to stick to your way with a SQL script per patch and just store all statements in the database... [snip] ... have system triggers that log all DDL statement against particular objects
I love this idea. I think this has got a lot going for it. The big advantage of this technique is that the person writing the patch does not need to change the way they work in order for it to be implemented.
As part of the patch runner installation it can add a system trigger to the current schema that will log the changes to the schema as they occur. This detail log can state which object that has changed, the change that was made, and the patch that issued the change.
The trigger can be notified of which patch is currently running (as stated by Wilfred) by the patch runner logging the name of the current patch in a package variable, a temporary table or some other session specific temporary store.
Once the patch runner has completed it can then produce a report stating which changes were applied by that upgrade, grouped by table. It can produce a report of all changes ever made to the database. If so required it could list the changes classified by some arbitrary grouping of objects (system functional area / table sizes).
As Wilfred states, there is a downside to this... the data is in the database, rather than version control. It is generated after the change has been applied. However, this data can be made available in version control fairly easily. The simplest solution is to have the report run regularly on a development or test server. Copy the report into version control and away you go. If you're running a nightly build then this can be done automatically each night from the test server in advance of the codeset being tagged.
Alternatively you can provide a simple user interface in order to query this information more interactively. If, for example, you're developing browser based applications this will be a fairly simple tool to produce within your normal toolset.
Additionally, such a system DDL trigger can be used to report on ANY changes made to the database, not just those applied through the official upgrade process. Having produced reports that will list object changes from the database it would be a trivial task to change those reports to list any objects that have changed without being ran through the patch runner. It may be that in a strict environment a change made outside of the patch runner (and therefore the standard application upgrade) could be blocked. Obviously, any developer or DBA that knows the structure will be able to work around it without too much work, but this then means that you are certain that the person doing so is consciously making a change outside of the accepted process, rather than because they are not aware that such a process exists.
As I've stated earlier, on Wilfred's blog, I'm not sure our organisation has a need for the table centric view of the changes made to a database. In fact I strongly urge those people who do so to ask why it is they do. I'd love to hear the reasons why... I feel as though I'm missing something!
That said, I think the second solution proposed by Wilfred is spot on, and if we were looking to produce a table centric view we would definitely follow that avenue first.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, Wilfred+van+der+Deijl, patch
I think I've made it obvious in the past that I massively favour the functional grouping, since I think it makes the job of the developer and the person performing the upgrade that much clearer. However, I acknowledge the perceived need for a table history, and started thinking about how you might produce it.
Just as I was getting to some sort of conclusion, Wilfred put together a couple of great ideas... and I thought I'd give them a critical review.
Forgive me for this Wilfred... I really wanted to get this down, I think it's a great topic!
Group the patches by table, then add interpreted comments to the files in order to state which patch a given ALTER TABLE statement belongs with
I'm not sure about this solution for a simple reason. I don't like organising the source files by tables; I think this makes the developer's job that much harder.
In producing a patch the developer needs to update several files and cannot easily see the order in which these changes are applied.
I simple situation where this becomes very important is where a column needs to be moved from one table to another. In order to do so, I cannot see how this can be done without changing at least two files; one that adds the new column, and one that drops the old.. In addition, you need to find somewhere to put the data migration script. Does this go into to the DDL file for the table having the column added? Or do you could add a third file into the mix.
I have found in the past that the create column and data migration get put into the table scripts and there is a manual process added to ensure that the existing column gets dropped. The process is then forgotten in the heat of the production upgrade and the redundant column remains in the schema.
In addition, with the table centric grouping it is easy for a developer to miss a step in the DDL, a column isn't added to a table, for example. By having the functional grouping it's easier to spot this mistake since the developer has a single file that lists all the DDL applicable for that functional change.
Finally, there is a need to add that extra step... adding the comments to the table create scripts. I have an objection to this in the same way that I have an objection to JavaDoc comments. People simply don't add them, and nobody notices / cares until such time as those missing comments are crucial. By then it's too late. The comments could be policed, but whenever I see something that needs policing I see something that needs changing so the policing is no longer needed.
Another way would be to stick to your way with a SQL script per patch and just store all statements in the database... [snip] ... have system triggers that log all DDL statement against particular objects
I love this idea. I think this has got a lot going for it. The big advantage of this technique is that the person writing the patch does not need to change the way they work in order for it to be implemented.
As part of the patch runner installation it can add a system trigger to the current schema that will log the changes to the schema as they occur. This detail log can state which object that has changed, the change that was made, and the patch that issued the change.
The trigger can be notified of which patch is currently running (as stated by Wilfred) by the patch runner logging the name of the current patch in a package variable, a temporary table or some other session specific temporary store.
Once the patch runner has completed it can then produce a report stating which changes were applied by that upgrade, grouped by table. It can produce a report of all changes ever made to the database. If so required it could list the changes classified by some arbitrary grouping of objects (system functional area / table sizes).
As Wilfred states, there is a downside to this... the data is in the database, rather than version control. It is generated after the change has been applied. However, this data can be made available in version control fairly easily. The simplest solution is to have the report run regularly on a development or test server. Copy the report into version control and away you go. If you're running a nightly build then this can be done automatically each night from the test server in advance of the codeset being tagged.
Alternatively you can provide a simple user interface in order to query this information more interactively. If, for example, you're developing browser based applications this will be a fairly simple tool to produce within your normal toolset.
Additionally, such a system DDL trigger can be used to report on ANY changes made to the database, not just those applied through the official upgrade process. Having produced reports that will list object changes from the database it would be a trivial task to change those reports to list any objects that have changed without being ran through the patch runner. It may be that in a strict environment a change made outside of the patch runner (and therefore the standard application upgrade) could be blocked. Obviously, any developer or DBA that knows the structure will be able to work around it without too much work, but this then means that you are certain that the person doing so is consciously making a change outside of the accepted process, rather than because they are not aware that such a process exists.
As I've stated earlier, on Wilfred's blog, I'm not sure our organisation has a need for the table centric view of the changes made to a database. In fact I strongly urge those people who do so to ask why it is they do. I'd love to hear the reasons why... I feel as though I'm missing something!
That said, I think the second solution proposed by Wilfred is spot on, and if we were looking to produce a table centric view we would definitely follow that avenue first.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, Wilfred+van+der+Deijl, patch
Rant: You want my money?
To all you companies out there that want to take my money, and want me to pay you by credit card, on the internet. When you ask for my credit card number, you've got three choices:
1 - Build the entryboxes so that it doesn't matter if I put spaces or dashes in, just let my format the number 1234-1234-1234-1234, strip the number out and just use that.
2 - Build the entry boxes so that I can't put spaces, dashes or too many characters in and make it clear that I can't. That way I'll type my credit card number with just the numbers.
3 - Let me type a combination of spaces, dashes and numbers in the way that's natural to me, then tell me I'm an idiot. Give me messages like "Your credit card number has too many characters, please try again", or (my personal favourite) "You have entered your card number with spaces, please enter just numbers".
Guess which option will reduce the chances of me using your company next time. Guess which option your company most likely uses.
1 - Build the entryboxes so that it doesn't matter if I put spaces or dashes in, just let my format the number 1234-1234-1234-1234, strip the number out and just use that.
2 - Build the entry boxes so that I can't put spaces, dashes or too many characters in and make it clear that I can't. That way I'll type my credit card number with just the numbers.
3 - Let me type a combination of spaces, dashes and numbers in the way that's natural to me, then tell me I'm an idiot. Give me messages like "Your credit card number has too many characters, please try again", or (my personal favourite) "You have entered your card number with spaces, please enter just numbers".
Guess which option will reduce the chances of me using your company next time. Guess which option your company most likely uses.
Friday, August 05, 2005
The Database Patch Runner - Rollbacks
In response to my earlier post here, Andrew Beacock asked a couple of seemingly small questions.
First of all, he asked for more detail. I'm going to address that in a later post.
The second question, I didn't really expect. He basically asked “How do you rollback a patch?”
I'm assuming that he's asked this question in relation to the point I made that went along these lines: Since the patch runner stops running patches whenever one of the fails, then recovery is simply a case of rolling back the changes that the patch had already made and then restarting the patch runner. If the runner ensures it doesn't attempt to re-run any successful patches, but does re-run the failed one then it effectively picks up from where it left off and goes on its merry little way.
The point I was trying to make was that since the patch runner stops, then you don't get into the situation where you're attempting to fix a problem that occurred half way through the upgrade by getting to the end that then picking up the mess it left in its wake. Instead you know where the upgrade failed, the patch log states it clearly; you know what the patch was trying to do, since you have a functional grouping of changes in the patch, and this gives you context for the failed change; you know that you only have to worry about the failure that is reported, not the hidden data problems that the rest of the upgrade generated because the first patch didn't do its job properly.
So how do you rollback the changes in order to get the patch up and running again?
To be honest, there's nothing I can think of other than getting your hands dirty; rolling up your sleeves and getting into the database. Picking apart what happened, piecing together the story and trying to gaffer tape up the problems.
However, you can make that job easier:
The big thing is... Think about transactions in your patch
Every DDL statement issues an implicit COMMIT, so don't pepper your patch with DDL, leaving data in a transient state committed in the database. Think about the order in which you do things in order to reduce the chances that a failure at any given point leaves data in an invalid state.
Ensure that your 'add to schema' DDL comes first. That way, if you're moving two columns between tables, and the second column's create fails, you don't get stuck in a situation where you need to reverse the first change or apply the second one manually.
Ensure that your 'remove from schema' DDL comes last. For the same reason as above. It's much easier to deal with if you know that your data migrations have completed and it's just a case of removing those columns manually and marking the patch as complete.
If you can get away with it, don't issue commits in your patch's data migration until it's completed. Admitted, if you're moving millions of rows of data around, this may not be possible. But think about it... do you really need to issue that commit every 10,000 records, or can you get away with running the whole lot through first? That way, when you get a failure, the patch runner can ROLLBACK and you know what state the data is in... the state it was before the patch started.
If you can't get away without committing regularly, or the patch simply takes to long to risk having to repeat it, think about how you can make the migration restartable. That is, store a watermark, make your patch keep track of where it was so that it can restart after a failure. Make sure that the patch can handle being restarted without it trying to re-do work it has already done. If it really is that risky, why not check that you have enough space in your rollback segments before you generate GBytes of data?
Ideally you want to make sure that your patch doesn't fail, but with a bit of thought before you write the patch, you can make your life easier when it does.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch
First of all, he asked for more detail. I'm going to address that in a later post.
The second question, I didn't really expect. He basically asked “How do you rollback a patch?”
I'm assuming that he's asked this question in relation to the point I made that went along these lines: Since the patch runner stops running patches whenever one of the fails, then recovery is simply a case of rolling back the changes that the patch had already made and then restarting the patch runner. If the runner ensures it doesn't attempt to re-run any successful patches, but does re-run the failed one then it effectively picks up from where it left off and goes on its merry little way.
The point I was trying to make was that since the patch runner stops, then you don't get into the situation where you're attempting to fix a problem that occurred half way through the upgrade by getting to the end that then picking up the mess it left in its wake. Instead you know where the upgrade failed, the patch log states it clearly; you know what the patch was trying to do, since you have a functional grouping of changes in the patch, and this gives you context for the failed change; you know that you only have to worry about the failure that is reported, not the hidden data problems that the rest of the upgrade generated because the first patch didn't do its job properly.
So how do you rollback the changes in order to get the patch up and running again?
To be honest, there's nothing I can think of other than getting your hands dirty; rolling up your sleeves and getting into the database. Picking apart what happened, piecing together the story and trying to gaffer tape up the problems.
However, you can make that job easier:
The big thing is... Think about transactions in your patch
Every DDL statement issues an implicit COMMIT, so don't pepper your patch with DDL, leaving data in a transient state committed in the database. Think about the order in which you do things in order to reduce the chances that a failure at any given point leaves data in an invalid state.
Ensure that your 'add to schema' DDL comes first. That way, if you're moving two columns between tables, and the second column's create fails, you don't get stuck in a situation where you need to reverse the first change or apply the second one manually.
Ensure that your 'remove from schema' DDL comes last. For the same reason as above. It's much easier to deal with if you know that your data migrations have completed and it's just a case of removing those columns manually and marking the patch as complete.
If you can get away with it, don't issue commits in your patch's data migration until it's completed. Admitted, if you're moving millions of rows of data around, this may not be possible. But think about it... do you really need to issue that commit every 10,000 records, or can you get away with running the whole lot through first? That way, when you get a failure, the patch runner can ROLLBACK and you know what state the data is in... the state it was before the patch started.
If you can't get away without committing regularly, or the patch simply takes to long to risk having to repeat it, think about how you can make the migration restartable. That is, store a watermark, make your patch keep track of where it was so that it can restart after a failure. Make sure that the patch can handle being restarted without it trying to re-do work it has already done. If it really is that risky, why not check that you have enough space in your rollback segments before you generate GBytes of data?
Ideally you want to make sure that your patch doesn't fail, but with a bit of thought before you write the patch, you can make your life easier when it does.
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch
Comments back
Comments should be running normally again now. The offending Haloscan comments javascript has been replaced with the original Blogger javascript.
I had inadvertently switched over to Haloscan comments without switching off the Blogger comments. So adding a comment when you arrived from a permalink and clicking on 'Post a comment' gave you a Blogger comment that couldn't be seen from the main page.
Ah well, you live and learn! Normal commenting has now been resumed.
I had inadvertently switched over to Haloscan comments without switching off the Blogger comments. So adding a comment when you arrived from a permalink and clicking on 'Post a comment' gave you a Blogger comment that couldn't be seen from the main page.
Ah well, you live and learn! Normal commenting has now been resumed.
Thursday, August 04, 2005
Comment problems
Just so you know, I'm having trouble with the comments on here...
I've managed to install two competing sets of comments.
Haloscan is dealing with the comments of the main page, then Blogger is dealing with the comments that you see when you look at an individual post. Look at this post and you'll see what I mean.
Over the weekend I'll try to make sure I fix the problem...
For now, please accept my apologies :-)
I've managed to install two competing sets of comments.
Haloscan is dealing with the comments of the main page, then Blogger is dealing with the comments that you see when you look at an individual post. Look at this post and you'll see what I mean.
Over the weekend I'll try to make sure I fix the problem...
For now, please accept my apologies :-)
The Database Patch Runner
Over here Wilfred van der Deijl has raised the time old question when dealing with databases.
How do you easily upgrade a database from an arbitrary version to a new particular version with the smallest amount of effort.
I responded with a brief description here , which caused Amihay Gohen to ask a question or two over E-mail. I thought I'd put together something a little more coherent and detailed here, rather than just send it on to Amihay directly.
This is the basic solution...
Whenever a developer / pair of developers need to change the database they write a patch. This patch contains any alter tables / data migrations / etc. A single file contains the full set of changes for a single conceptual change and may cover changes to several tables.
The patches are written in PL/SQL procedures. That is, each single set of changes is implemented in a single procedure. Each DDL command is issued in an EXECUTE IMMEDIATE, or similar, as is any DML that references a table or column that does not yet exist. The patch is written in a procedure so that we can use the Oracle exception handler to propagate fatal errors in the code to a controlling procedure, something that is far more difficult to do in a script.
These patch procedures are then installed by a "patch runner". This runner is guided by a .txt list of patches that is created by the developers. If a developer wants to add a patch then they write the procedure and add it to the patch list. The runner then uses this patch list to tell it which patches need to be installed, and in what order. The runner is written in PL/SQL, using UTL_FILE and DBMS_SQL to install the procedures.
The runner logs when a patch starts, in a table, and marks the completion or failure of that patch when it finishes. By looking in the patch log before it runs a patch, the patch runner ensures that it never attempts to run a patch that has previously been marked as complete.
In addition, if any patch fails then the patch runner aborts, stating that it failed. "Crash don’t trash!". If the patch runner is restarted then it will attempt to re-run any patches that previously failed. This makes it easier to restart a failed upgrade if ever required. You reverse out the changes already made by the failed patch and then rerun the patch runner.
The runner itself is installed in a single PL/SQL script, and we make sure that it installs all the components it needs before it starts, and tears itself down once its finished. It does not rely on any other part of the database or application in order to work. Since there are no dependencies outside of the patch runner install script, we can use a single patch runner for all of our database based applications, with no changes.
The installation and upgrade of the patch_log table is dealt with in the more traditional manner of a single CREATE TABLE at the start followed by ALTER TABLE statements as it changes over time. The patch log is not destroyed down with the runner.
So, in summary, you check out a given tagged version of the application to run against an arbitrary database and run the patch runner. It loads the list of patches that are applicable for that tagged version. It runs over each patch in turn and checks if it has previously ran. If it has not, then it runs the patch.
By the time it reaches the end of the list it has ran all the patches, none of them twice. You can even run the patch runner twice in succession and guarantee that the second run will not change the state of the database.
The key to that is then to make sure that you use the build often. Get your developers their own database workspaces and make sure that that rebuild and upgrade them often. By repeating the upgrades often you ensure that they basically work before they get moved into a test environment with the bigger worry of large volumes of data.
The patch runner is, of course, only a small part of the database build, and a smaller part of the whole application build. So the runner needs to put into the context of a larger build script. We use batch files here in order to manage our database build process, but I see no reason why other, for complete scripting languages shouldn't be used, or ANT. The runner is, after all, just a PL/SQL script.
As an aside, we also write tests for the patches, checking the pre and post conditions are valid… but that’s a very different topic!
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, patch, Robert+Baillie, Wilfred+van+der+Deijl, Amihay+Gohen
How do you easily upgrade a database from an arbitrary version to a new particular version with the smallest amount of effort.
I responded with a brief description here , which caused Amihay Gohen to ask a question or two over E-mail. I thought I'd put together something a little more coherent and detailed here, rather than just send it on to Amihay directly.
This is the basic solution...
Whenever a developer / pair of developers need to change the database they write a patch. This patch contains any alter tables / data migrations / etc. A single file contains the full set of changes for a single conceptual change and may cover changes to several tables.
The patches are written in PL/SQL procedures. That is, each single set of changes is implemented in a single procedure. Each DDL command is issued in an EXECUTE IMMEDIATE, or similar, as is any DML that references a table or column that does not yet exist. The patch is written in a procedure so that we can use the Oracle exception handler to propagate fatal errors in the code to a controlling procedure, something that is far more difficult to do in a script.
These patch procedures are then installed by a "patch runner". This runner is guided by a .txt list of patches that is created by the developers. If a developer wants to add a patch then they write the procedure and add it to the patch list. The runner then uses this patch list to tell it which patches need to be installed, and in what order. The runner is written in PL/SQL, using UTL_FILE and DBMS_SQL to install the procedures.
The runner logs when a patch starts, in a table, and marks the completion or failure of that patch when it finishes. By looking in the patch log before it runs a patch, the patch runner ensures that it never attempts to run a patch that has previously been marked as complete.
In addition, if any patch fails then the patch runner aborts, stating that it failed. "Crash don’t trash!". If the patch runner is restarted then it will attempt to re-run any patches that previously failed. This makes it easier to restart a failed upgrade if ever required. You reverse out the changes already made by the failed patch and then rerun the patch runner.
The runner itself is installed in a single PL/SQL script, and we make sure that it installs all the components it needs before it starts, and tears itself down once its finished. It does not rely on any other part of the database or application in order to work. Since there are no dependencies outside of the patch runner install script, we can use a single patch runner for all of our database based applications, with no changes.
The installation and upgrade of the patch_log table is dealt with in the more traditional manner of a single CREATE TABLE at the start followed by ALTER TABLE statements as it changes over time. The patch log is not destroyed down with the runner.
So, in summary, you check out a given tagged version of the application to run against an arbitrary database and run the patch runner. It loads the list of patches that are applicable for that tagged version. It runs over each patch in turn and checks if it has previously ran. If it has not, then it runs the patch.
By the time it reaches the end of the list it has ran all the patches, none of them twice. You can even run the patch runner twice in succession and guarantee that the second run will not change the state of the database.
The key to that is then to make sure that you use the build often. Get your developers their own database workspaces and make sure that that rebuild and upgrade them often. By repeating the upgrades often you ensure that they basically work before they get moved into a test environment with the bigger worry of large volumes of data.
The patch runner is, of course, only a small part of the database build, and a smaller part of the whole application build. So the runner needs to put into the context of a larger build script. We use batch files here in order to manage our database build process, but I see no reason why other, for complete scripting languages shouldn't be used, or ANT. The runner is, after all, just a PL/SQL script.
As an aside, we also write tests for the patches, checking the pre and post conditions are valid… but that’s a very different topic!
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, patch, Robert+Baillie, Wilfred+van+der+Deijl, Amihay+Gohen
Monday, August 01, 2005
Oracle Firefox
Whilst it doesn't give you anything that a bookmark doesn't give you anyway, that little search box next to the address bar still feels pretty handy.
And if you're an Oracle developer, then tahiti.oracle.com is pretty handy too.
Well, someone out there has put the two together here.
Not sure I'll use it that often, but it's worth a look!
Update: 25/01/06
Turns out I use this absolutely loads. If you haven't installed it yet... get it on!
Technorati Tags: Oracle, Firefox, extension, oracle+documentation, Mozilla, Robert+Baillie, Eddie+Awad
And if you're an Oracle developer, then tahiti.oracle.com is pretty handy too.
Well, someone out there has put the two together here.
Not sure I'll use it that often, but it's worth a look!
Update: 25/01/06
Turns out I use this absolutely loads. If you haven't installed it yet... get it on!
Technorati Tags: Oracle, Firefox, extension, oracle+documentation, Mozilla, Robert+Baillie, Eddie+Awad
Saturday, July 30, 2005
Some screenshots of the Haloscan Ping Firefox Extension
The configuration screen...

And the Ping Screen...

Technorati Tags: Robert+Baillie,Andrew+Beacock Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
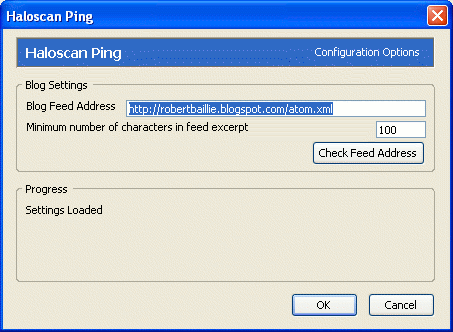
And the Ping Screen...
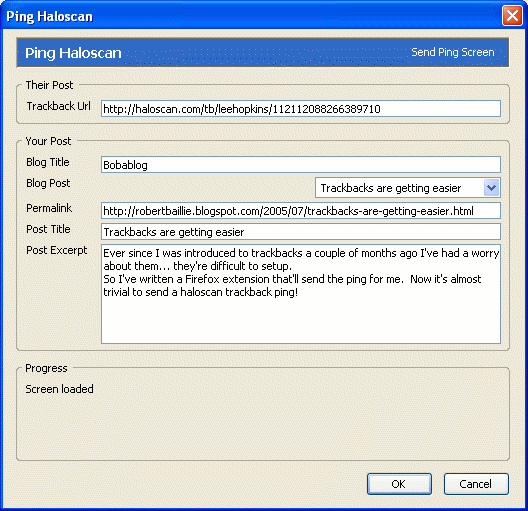
Technorati Tags: Robert+Baillie,Andrew+Beacock Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
Trackbacks are getting easier
Ever since I was introduced to trackbacks a couple of months ago I've had a worry about them... they're difficult to setup. So I thought I'd do something about it.
After a bit of help from my good friend Andrew Beacock, I got my head around trackbacks and set up a Haloscan account so I could get them installed onto my own blog. Getting it up and running was pretty straight forward, but then the tricky bit arrived... actually performing a trackback ping request.
In order to make a request you need to go to the Haloscan account and enter the trackback ping URL for the post that you want to ping. You then need to enter the details of your own blog... the blog title, post link, title and extract. It all seemed like a lot of hard work to me.
So here's what I did:
I wrote a Firefox extension to send trackback ping requests to Haloscan
In order to use it you need to set it up:
In order to send a ping request:
Simple as that!
At the moment I'd regard the extension as being at alpha stage, so for now I'm sending it out on request. If you'd like to try it out then mail me and I'll send you a copy.
Once I've got some positive feedback for it I'll try to publish it on Mozilla Update and Mozdev.
Update:You can mail me here...
Technorati Tags: Robert+Baillie,Andrew+Beacock Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
After a bit of help from my good friend Andrew Beacock, I got my head around trackbacks and set up a Haloscan account so I could get them installed onto my own blog. Getting it up and running was pretty straight forward, but then the tricky bit arrived... actually performing a trackback ping request.
In order to make a request you need to go to the Haloscan account and enter the trackback ping URL for the post that you want to ping. You then need to enter the details of your own blog... the blog title, post link, title and extract. It all seemed like a lot of hard work to me.
So here's what I did:
I wrote a Firefox extension to send trackback ping requests to Haloscan
In order to use it you need to set it up:
- Install the extension
- Configure it with the address of your blog feed (rss and atom are supported). You'll find it under Tools -> Haloscan Ping
- Log into Haloscan
In order to send a ping request:
- Write your blog entry and publish it
- Go to the blog you want to ping, and select the trackback URL
- Right-click and pick Ping Haloscan
- Pick the entry from your blog to ping with and click OK
Simple as that!
At the moment I'd regard the extension as being at alpha stage, so for now I'm sending it out on request. If you'd like to try it out then mail me and I'll send you a copy.
Once I've got some positive feedback for it I'll try to publish it on Mozilla Update and Mozdev.
Update:You can mail me here...
Technorati Tags: Robert+Baillie,Andrew+Beacock Firefox, extensions, Haloscan, trackback, Mozilla, browser, internet, web, blog, software, tech, technology
Friday, July 29, 2005
Index Cards
In our version of XP, Stories get written on index cards.
Text on the front, in big marker pen describes the user action in a single sentence.
The aim is to get the people involved to think in small chunks, and to think about the fundamentals of each piece of work.
Text on the back, in biro describes any particular behaviour required, we call them the acceptance criteria. The aim is to get people to think about the exceptional requirements of a story, the bits that the simple view of the action doesn't cover, to think of the little gotchas that'll appear.
They work extremely well, focussing the mind on the job in hand.
But there's something I think we've missed the point of: For each story there is only one card.
Here are my thoughts...
Since there's only one card, the card needs to be with the people that are currently working on it. If the story's still being worked out, it's with the customer, if it's being developed then it's with the pair working on it.
That means that if the customer wants to change their mind after the story's been started by the development team then they need to find the pair that's currently working on it and speak to them.
Fair enough, we could have the stories stored electronically and then put a system in place to ensure that the pair are notified of any change as soon as its put onto the system. It wouldn't be difficult, the customer enters each story on the system, revising it until they think it's ready. The story gets marked as ready to start when they've had a discussion with the development team. Each pair would register which story they're working on, marking the story as in progress. And so, and so on.
Or, we could do the simple thing and use natural capabilities of the card; do the simplest thing that will work.
Simplicity is only part of the issue. The big advantage of actually tracking down the pair and speaking to them is that you then get into a conversation. A notification is one way, a conversation is two way. And things that are written down are open to interpretation.
Conversation is crucial to the success of XP, and keeping the story on the card just seems to me to be a great way of keeping that conversation going.
Technorati Tags: Robert+Baillie, Extreme+Programming, user+stories
Text on the front, in big marker pen describes the user action in a single sentence.
The aim is to get the people involved to think in small chunks, and to think about the fundamentals of each piece of work.
Text on the back, in biro describes any particular behaviour required, we call them the acceptance criteria. The aim is to get people to think about the exceptional requirements of a story, the bits that the simple view of the action doesn't cover, to think of the little gotchas that'll appear.
They work extremely well, focussing the mind on the job in hand.
But there's something I think we've missed the point of: For each story there is only one card.
Here are my thoughts...
Since there's only one card, the card needs to be with the people that are currently working on it. If the story's still being worked out, it's with the customer, if it's being developed then it's with the pair working on it.
That means that if the customer wants to change their mind after the story's been started by the development team then they need to find the pair that's currently working on it and speak to them.
Fair enough, we could have the stories stored electronically and then put a system in place to ensure that the pair are notified of any change as soon as its put onto the system. It wouldn't be difficult, the customer enters each story on the system, revising it until they think it's ready. The story gets marked as ready to start when they've had a discussion with the development team. Each pair would register which story they're working on, marking the story as in progress. And so, and so on.
Or, we could do the simple thing and use natural capabilities of the card; do the simplest thing that will work.
Simplicity is only part of the issue. The big advantage of actually tracking down the pair and speaking to them is that you then get into a conversation. A notification is one way, a conversation is two way. And things that are written down are open to interpretation.
Conversation is crucial to the success of XP, and keeping the story on the card just seems to me to be a great way of keeping that conversation going.
Technorati Tags: Robert+Baillie, Extreme+Programming, user+stories
Wednesday, July 27, 2005
The second saddest post ever
The other thing I love about regular expressions is that you can NEVER test them enough. You always find yet another bit of text that doesn't behave itself. There's always better ways of doing what you're doing. And if you ever post a blog entry about one, you always have to follow it up with another that corrects it...
Damn!
[\w\W]{200,}?[\.!\?\)"\n\r]+
Damn!
RTFM (again)
When I first started pair programming it took me about 2 hours to come to terms with the fact that sometimes you need to ask for help, and that it's OK to look in a manual. You won't lose face with your pair for doing that.
It took our boss about 2 weeks to notice the increase in traffic on uk.php.net caused by my arrival.
So why is it that whenever I'm coding on my own I will tend to try to hack through the undergrowth with a pen knife to get to the solution rather than ask someone if I can borrow their chainsaw?
The latest example is a problem I was having with a firefox extension.
I wanted the user to be able to select a piece of text, right click, pick my extension and have a dialog box where one of the fields contains the selected text.
Since I already knew how to do this I flew straight in and spent ages fiddling round in the dialog box's code with parent.getSelection(), parent.window.getSelection, parent.window.context.getSelection() and every other combination including parents, windows and selections that I could think of. Not a chance.
For some reason I couldn't get the text from the parent window. I suspect that firefox does not regard the window the user sees as the parent window, but I've not bothered looking to find out...
Anyway, quite early on in I thought to mayself:
'This would be easy if you could just pass arguments into the dialog box. I could just get the selection in the code that kicks off the dialog box and there we go'.
But since I knew window.open I knew this wasn't possible.
An hour later I decided to take a look at openDialog, which is the call I was actually making to open the window. It turned out that yep, you can pass arguments into the child dialog box.
If only I'd just accepted that I don't know everything and looked at it an hour earlier I'd have saved myself a lot of stress.
Note to self... RTFM!
It took our boss about 2 weeks to notice the increase in traffic on uk.php.net caused by my arrival.
So why is it that whenever I'm coding on my own I will tend to try to hack through the undergrowth with a pen knife to get to the solution rather than ask someone if I can borrow their chainsaw?
The latest example is a problem I was having with a firefox extension.
I wanted the user to be able to select a piece of text, right click, pick my extension and have a dialog box where one of the fields contains the selected text.
Since I already knew how to do this I flew straight in and spent ages fiddling round in the dialog box's code with parent.getSelection(), parent.window.getSelection, parent.window.context.getSelection() and every other combination including parents, windows and selections that I could think of. Not a chance.
For some reason I couldn't get the text from the parent window. I suspect that firefox does not regard the window the user sees as the parent window, but I've not bothered looking to find out...
Anyway, quite early on in I thought to mayself:
'This would be easy if you could just pass arguments into the dialog box. I could just get the selection in the code that kicks off the dialog box and there we go'.
But since I knew window.open I knew this wasn't possible.
An hour later I decided to take a look at openDialog, which is the call I was actually making to open the window. It turned out that yep, you can pass arguments into the child dialog box.
If only I'd just accepted that I don't know everything and looked at it an hour earlier I'd have saved myself a lot of stress.
Note to self... RTFM!
Tuesday, July 26, 2005
CSS Rules
We love CSS here, we try to use it as much as possible to ensure that the look and feel of our application is easily skinnable. We're pretty good at it, and we get by.
This guy though... now HE knows what he's doing :-)
UK Flag in CSS only
This guy though... now HE knows what he's doing :-)
UK Flag in CSS only
Hardware Tokens
In our office, we all sit around a couple of sets of desks. You may say that we're definitely not 'geographically challenged'. Each pair can pretty clearly see every other pair.
We don't store any source code on our local machines. Since we're developing a PHP application we need to deliver it though a web server and it access a nice big Oracle database, and guess what... we've got a whole department geared up to supporting web servers and databases. So we don't have local installs of databases and webservers, we don't administrate them, and none of us want to.
So our workspaces live on a network drive. Yep, Win CVS is a bit of a pain over a network, but for now we're living with it. Our PHP files live on a web server so we can access them without running any uploads or anything.
We've given our workspaces numbers, prefixed with the name of the project. The source code lives in a folder with the name of the workspace and the database lives in a schema with the name of the workspace. Your pair is working in workspace 'Laurel1', you get set of source code 'Laurel1' and database schema 'Laurel1'. Nice and simple.
The only problem is, if no one individual owns a particular workspace, then how do we know which pair is allowed to work in which workspace?
We have mutually exclusive hardware tokens. Or, to put it another way... we have paper flags that we put into holsters taped onto the back of our flat screen monitors.
If you've got the Laurel1 flag then you've got the Laurel1 workspace, and only your pair is allowed to change the workspace.
If you 've not got the Laurel1 flag then you can't change the Laurel1 workspace.
Since everyone's living so close, it's easy to see the flags. In the very rare situation where a pair is working remotely, they phone up a proxy to get their flag, a humorous effigy is made of one of the pair, and the flag is given to the effigy.
We have a spare workspace too...
We call it integrate*. It's the workspace where the integration takes place. In order to do a large scale commit you must have the integrate workspace token. If you don't then you don't commit. The pair with the token is the pair that's currently doing an integration. It has the advantage of a separate build machine since you're forced to check in from your dev space and check out to the integrate space and everyone can see you're doing it.
Our hardware tokens make it easy to see who's working where.
And they were fun to make.
Technorati Tags: Robert+Baillie, Extreme+Programming, pair+programming, workspaces, development
* actually, we call it autotest, but if we got a new one we'd call it integrate... honest.
We don't store any source code on our local machines. Since we're developing a PHP application we need to deliver it though a web server and it access a nice big Oracle database, and guess what... we've got a whole department geared up to supporting web servers and databases. So we don't have local installs of databases and webservers, we don't administrate them, and none of us want to.
So our workspaces live on a network drive. Yep, Win CVS is a bit of a pain over a network, but for now we're living with it. Our PHP files live on a web server so we can access them without running any uploads or anything.
We've given our workspaces numbers, prefixed with the name of the project. The source code lives in a folder with the name of the workspace and the database lives in a schema with the name of the workspace. Your pair is working in workspace 'Laurel1', you get set of source code 'Laurel1' and database schema 'Laurel1'. Nice and simple.
The only problem is, if no one individual owns a particular workspace, then how do we know which pair is allowed to work in which workspace?
We have mutually exclusive hardware tokens. Or, to put it another way... we have paper flags that we put into holsters taped onto the back of our flat screen monitors.
If you've got the Laurel1 flag then you've got the Laurel1 workspace, and only your pair is allowed to change the workspace.
If you 've not got the Laurel1 flag then you can't change the Laurel1 workspace.
Since everyone's living so close, it's easy to see the flags. In the very rare situation where a pair is working remotely, they phone up a proxy to get their flag, a humorous effigy is made of one of the pair, and the flag is given to the effigy.
We have a spare workspace too...
We call it integrate*. It's the workspace where the integration takes place. In order to do a large scale commit you must have the integrate workspace token. If you don't then you don't commit. The pair with the token is the pair that's currently doing an integration. It has the advantage of a separate build machine since you're forced to check in from your dev space and check out to the integrate space and everyone can see you're doing it.
Our hardware tokens make it easy to see who's working where.
And they were fun to make.
Technorati Tags: Robert+Baillie, Extreme+Programming, pair+programming, workspaces, development
* actually, we call it autotest, but if we got a new one we'd call it integrate... honest.
Monday, July 25, 2005
The saddest post ever
One of the things that I had to come to terms with about 18 months ago was the fact that I needed to understand regular expressions.
The Oracle world has yet to really embrace these strange beasts, and so I was completely hidden from their glory.
Now, I've reached the point where I'm going to do possibly the saddest thing in the whole world. I'm going to post a recent regular expression onto this blog... here... now.
For a soon to arrive firefox extension, I needed to extract a number of complete sentences from a piece of text that numbered at least 100 characters in length. Here's how I did it:
OK, if you use apostrophes as quotation marks it falls down a little, but then you deserve a slap anyway ;-)
For being so sad, I must now go and whip myself with a birch branch.
Updated: OK, so I'm hoping that it now deals with newlines properly as well ;-) Serves me right!
The Oracle world has yet to really embrace these strange beasts, and so I was completely hidden from their glory.
Now, I've reached the point where I'm going to do possibly the saddest thing in the whole world. I'm going to post a recent regular expression onto this blog... here... now.
For a soon to arrive firefox extension, I needed to extract a number of complete sentences from a piece of text that numbered at least 100 characters in length. Here's how I did it:
(.|\n){200,}?[\.!\?\)"\n\r]+
OK, if you use apostrophes as quotation marks it falls down a little, but then you deserve a slap anyway ;-)
For being so sad, I must now go and whip myself with a birch branch.
Updated: OK, so I'm hoping that it now deals with newlines properly as well ;-) Serves me right!
Subscribe to:
Posts (Atom)