Well, that busiest of weeks is finally over, and I'm getting back into working life.
After a week of flying down powder runs in the French Alps, I managed to complete my first (and last) half marathon in a phenominal 2 hours, 17 minutes and 49 seconds.
If that wasn't enough, I then followed it up with my first public presentation, to
UK OUG, as part of their combined SIG day.
It was a great experience, and I can't thank
Andrew Clarke enough for inviting me to speak, as well as Penny for putting up with me chopping and changing the presentation at the last minute.
The full script for the presentation should make it on to the
UK OUG site in the next day or two (pdf hopefully), but for those that can't wait (honestly... can you REALLY not wait), the full text is repeated below.
The highlight was most definately the demonstration of
SQL Developer (AKA Raptor) by
Sue Harper, a product manager who has most definately got her head screwed on right. It's good to hear Oracle making the right noises, and SQL Developer seems to be a clear tool developed in an environment of customer collaboration. Quest should really be watching their backs...
Also, Ivan Pellegrin's talk on service oriented architecture was quite enlightening, demystifying the principles of SOA, clearly cutting through the hype and revealing the important concepts... reusability, transparency and simplicity.
For those that wanted to catch me at the bar, please accept my most humble of apologies. I had somewhere to which I needed to run, and couldn't avoid. If you have any questions... any at all... please mail me and I'll happily open up some correspondance. If it's appropriate I'll post the responses on this site.
Also, Any feedback, even negative, is more than appreciated!
UK OUG presentation
March 14th 2006 – 12:45pm
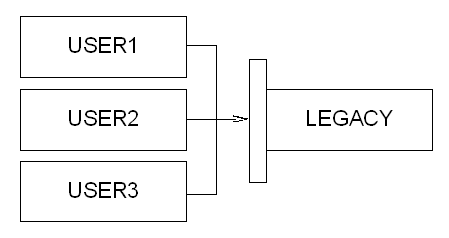
Lessons from an Agile projectIntroductionFor the last 18 months I've been team leading a project to replace a legacy Oracle and Powerbuilder system with an Oracle and PHP system. The requirements were that over the coming 3 years or so we would completely replace the existing functionality of the legacy system, and enhance the system where-ever the business thought it could gain competitive advantage.
We were told that we should expect to be able to release components of the new system with very short notice, basically whenever the business thought we had something it could use, that the direction of the project was likely to change frequently during its course and that at all times our new system would have to access the same data the legacy system does, that the data must be completely in step at all times.
Basically, the project is the same as every other project I've ever worked on. It's just that the organisation was honest about it up front.
To cut a long story short, we've had a pretty successful 18 months. In that time we've replaced about half the legacy system, and we've added a whole load of bells and whistles that the business feels has had a tangible effect on practices, turnover and, most importantly, profit.
We've had more good feedback from the 500 or so end users than I've ever heard from any other set of end users in my life, and I've got to say that all in the new system is more than liked by those that use it.
We get a constant feed of new ideas from the shop floor, and we have a dedicated customer team who are great at filtering those requests and combining them with the board of director's strategic view of the project. The result is a very clear short term development direction and a feeling that we know where we're generally headed.
We've made 4 releases of the system to the business now, averaging one every 4 or 5 months, and every time we've made those releases we've made them to 12 independent installations of the system. That is, in the last 18 months our system has been released into a production environment nearly 50 times.
We've never had a release fail.
We made a major release of the system about two weeks ago, and since it's been released the users have reported 2 bugs. Which we've fixed and released, which makes our current outstanding live bug count zero.
As we've been working on the system we've made a few demo releases. In fact, every time we finish a small piece of functionality we release it to the demo environment.
That equates to an average of one release every two days... a total of about 300.
Often, the customer team will come up with an idea for a new piece of functionality, and if they think it's important enough, it can be specced, coded, tested and released into the demo environment within 3 or 4 days.
Basically, we're working in line with the principles of Extreme Programming, and I can honestly say that I've never worked on a project that has been any where near as successful as this.
Now, I firmly believe that internal system development is perfectly suited to Extreme Programming and vice versa, and I could very easily spend all day up here talking about how XP works and the advantages it gives you. I can happily evangelise about the individual principles and practices that XP embodies and try to convince you that XP is the way forward.
But XP isn't for everyone. And XP probably isn't universal.
Instead I'd like to talk about what working on an XP project has taught me in a more general sense.
I'd like to talk about some core practices that we work with, that are complimentary to XP, and that I think are fundamental foundations upon which you can build a development environment.
That is, Extreme Programming encourages you to think about why the process and your practices are the way they are, to question their worth and in turn improve them.
Working on an XP project has taught me to take a new look at the practices I'd taken for granted. To examine the problems I thought were essential, rather than accidental, re-evaluate them, and hopefully solve them.
We've come up with some good practices that I think are are good whether you choose to pair program and unit test or not. That these are practices from which any development process will benefit, and for which I believe there are NO excuses for not following. Certainly none that I've heard.
These are things that are complimentary to any development process and that I think are probably unspoken assumptions of processes like XP.
These are things that I am worried may be 'no brainers' in the Java, .NET and Ruby, communities, but that we, as Oracle developers and DBAs need to learn.
My biggest hope is that as I'm describing these lessons, many or most of you will just think 'well yeah, of course, jeez, didn't you already know that', that many of you will go away in a 40 minutes time thinking, 'I learnt nothing from that, he just said a lot of stuff that's obvious'.
I hope that it's just me that's taken this long to learn these lessons.
I hope that my own experiences of Oracle development prior to this project are not the same as everyone else's.
I hope that I was just unlucky.
Understand version controlOn the face of it, version control tools are simple beasts. Technically, they do very few things:
• Record changes that have occurred to files - Commit.
• Allow you to extract the files as they appeared at any particular point in time - Checkout.
• Label particular points in time to be of interest - Tag.
• Manage multiple changes made to single files, at the same time, by multiple people – Lock or Merge.
• Segregate sets of changes from each other - Branch.
• Perform actions when commits occur - Trigger.
• Group changes together in a set and put comments against it.
All in all, the tools provide nothing that a manual process couldn't.
In fact, I've worked at a place that implemented a pessimistic locking version control system purely through manual processes and a directory structure on a network drive. We'd copy files, change their extensions to lock them, change their extensions to release them, copy folders to tag, copy them again to branch.
The result was a lot of time spent following the manual process, and fixing problems that were caused by people not following them. Every developer hated it. It sucked time out of your day and it was a dull, repetitive process that you could never get quite right.
But that wasn't because there was anything wrong with the processes they were trying to implement.
The problem was solely with the methods by which the processes were carried out.
That is, there are two parts to version control:
• Underlying processes that allow teams to manage changes to files over a period of time.
• Tools that help to make those processes easy to follow.
The process without the tool is laborious and cumbersome.
The tool without the process is, well, useless.
So often you see organisations that pick up the tool, but don't understand the principles behind it, or who understand the processes but don't get how the tool can help you perform them easily.
My old friends with the manual processes DID eventually pick up CVS, after I'd left, but then completely failed to marry up their old processes with the new tool and ended up alienating the developers in a different way. It was a bit of a shame, especially considering that the original processes were actually built on sound principles.
In order to really take advantage of version control you need to understand both those aspects. How the processes work, and how the tools can help you perform those processes so that the development team don't see them as a barrier to getting the job done.
In order to understand how to put a version control process together that works we need to understand why we need version control, and what it does for us.
For me, the most important aspect of version control is that when it's used properly, it becomes an absolute truth.
In order for the developers to work, they need an absolute truth that they can rely on. A place from which any piece of development can start. A good version control repository provides that. It allows a developer to take any source code file they need and say with a great deal of certainty,
"This is the file against which I must develop. This specification
relates to this set of files, and this is the truth from which I must
work".
In teams where the version control repository either doesn't exist, or is an unreliable source of the truth, developers will find an alternative truth. Most often this is either the live system (which is a particular, narrow truth), or their own world (which is almost always a lie).
So in order to make version control work for us, we need to make sure that it is reliable.
What do I mean by reliable?
First of all, we need to make sure that the team agree that from our version control we can build the live systems.
Regularly ask of your version control:
"If the live version of our system was to suddenly disappear,
along with all our backups, can I completely rebuild the structure
of our system from the version control repositories, and be
certain it's correct?"
If the answer is no then your repository is not good enough. Its content is unreliable in the sense that either:
• It does not hold all the information that it needs to, or
• The information it holds is inaccurate.
There is reliability of completeness.
And
There is reliability of accuracy.
Secondly, we need to make sure that the software in the repository is of a standard that all parties agree to.
It may be that all code in the repository must always be in a ready to release state and that the build never breaks, it may be that the code must be regarded as broken except during short periods of well defined time.
Whatever the decision is for the level of quality of code, it must be known throughout the team what that level is.
If not, a developer will avoid updating their workspace to the latest version of the code... they'd never know if doing so would create a whole swathe of bugs to appear.
There is reliability of quality.
Finally, we need to make sure that whenever a developer wants a particular version of a particular piece of code that they can reach it, easily.
Also, that whenever they need to check code into the repository that there is a way of them to do so, and that doing so takes a trivial amount of time.
The version control system and its standards should not stand in the way of the developers from reaching their goals, it should aid them. Its crucial that whatever standards and tools are put in place that they match the working practices of the team involved.
There is reliability of usefulness.
Without those things, the version control processes will never be perceived as anything more than a pointless chore that gets in the way. And when people think it gets in the way, there will always be people who will find ways around it. As soon as one developer works round it, it ceases to be the truth. As soon as the repository is no longer the truth, the whole idea of version control collapses.
The good news is that ensuring that the aspects of reliability are reached is really just about recognising that they're there and they're attainable. It's really just about understanding the relationship between the process and the tool and the impact their use has.
It's about developing a process that matches your aims and your team and then finding a tool that matches the process.
Thankfully there's plenty of good thinking out there that can help us put together appropriate processes, and there's one book in particular that really stands out:
Software Configuration Management Patterns by Steve Berczuk and Brad Appleton.
It's brilliant, and a must read for anyone that is looking to put version control processes in place, or wants to understand how they can improve the processes they have. Quite simply – if you haven't already, you should read it.
All in all, I can't understate how important I think the implementation of a good version control policy and tool is. I found that understanding how version control works on a conceptual level led us to put together a set of processes that really don't get in the way of developing code but ensure that the repository is a reliable truth.
And doing so led me very quickly onto the next lesson. Something that I didn't realise was possible until I'd seen the capabilities of a version control tool used inside a clear and robust process...
Implement a build script that an idiot could runThe most dangerous part of any database development is the bit where you roll it out onto a live server.
Because it's risky, many organisations think that they need highly skilled database developers or DBAs to perform the upgrade. That way, if anything goes wrong then you're guaranteed to have someone there to fix it.
It doesn't sound like a bad idea.
But because these people are highly skilled and able to keep track of the things that need doing during the upgrade, then you find that the upgrade becomes a series of disparate tasks. A long mundane series of steps. If you're really lucky then they may have a check-list beside them as they're doing it, but often they won't.
The problem is that when you have a developer or DBA producing and performing the upgrade, you end up with a build script that a developer or DBA can run. And that means it's a build script that needs a developer or DBA for it to be run, and that means its basically time consuming and difficult to run.
When anything is time consuming and difficult to do, then you do anything you can to avoid doing it. You do it as few times as you possibly can, and that leads to problems...
I've worked for far too many people who will run an upgrade on a live system that they have never ran anywhere else. That means that the most dangerous part of the system life cycle is effectively done without any testing.
Not only that, but I've worked for software houses that will do so and then have the cheek to charge the customer extra for support during the upgrade.
Looking back I can't understand how I accepted, and how everyone around me accepted that when you decide you're going to upgrade a database you need to spend a long time putting together a collection of scripts and then run them in an informal manner.
I've since interviewed a lot of developers and every single one has more or less said the same thing:
Upgrades are time consuming, untested, informal processes.
Now that sounds like a bad idea.
So, I've got an alternative.
Assume that you won't have highly skilled people running your builds on live systems.
Assume that the person performing the upgrade is an idiot.
If you've got an idiot performing the upgrade then in order to make the upgrade safe you need to make the build scripts safe. You can no longer rely on highly skilled DBA to nurse it through.
Basically, the build script has to be of as high a quality as any other piece of code in the system.
The build script needs to work first time, every time, and needs to do so with the minimum of input from the user. It needs to tell the person who's running it that it's working, that every component is doing what it should be doing, and as soon as it stops working it needs to stop and flash red and tell the idiot that the world's going to end... and then maybe stop and roll-back to a time when things were still working.
The code that forms the build need to be covered by proper testing strategies, fall under version control, and be held in a structure that everyone on the team understands and can support. As well as being trivial to run the build, it needs to be trivial to add to the build. You want all of your developers to be able to actively change the build themselves, not ask someone else to do it for
them. You want every developer to take personal responsibility for the quality of the build scripts in the same way that they take responsibility for the system.
When the developers have to ask a third party to produce the scripts for them there is the possiblity of misinterpretation. If the developers add the scripts themselves there is clarity and no risk of ambiguity.
I argue that if you need to, then you can put together a build script that an idiot can run. That doing so doesn't actually require much more work to do than producing a build script a DBA could run. And that doing so makes the build script easier to run, safer to release to live and far quicker to produce.
When you've got that it means that you have a build script that anyone can run, and can run easily.
We've got our build scripts to such a point that we can roll out any version of our system to any earlier version of our system by switching off the web server, running a single command with 3 parameters, waiting for the script to finish, and then switching the web server back on again.
If we need to create a brand new replica of the system, we take a configured web server and a fresh Oracle instance, and run the same script.
We use the same script to roll out to the demo environment as we do for the live environment and every developer working on the project will roll out the system to the demo environment every few days... that is, when they finish each piece of work.
This means that in a 3 month release cycle the upgrade scripts will have been ran, on average, 20 times by every developer on the team.
Having the developers run the scripts that often really helps in getting the build scripts to run smoothly, and with the minimum of effort. Ask a developer to do the same task every two days and if they're worth employing they'll do everything they can to make sure that task is trivial to perform.
We've done this by having a very clear structure for our build scripts. We've put a structure together that consciously removes the need for a build manager. That is, at every previous place I've worked there has been a person employed who's responsibility it is to construct a large chunk of the build script.
When a customer wanted a release, or a version was to be sealed, the build manager would go through the changes made between version x and version y. In some places this would mean checking through their e-mails, in others it would mean checking differences in the version control repository, in yet others it would be checking the differences between reference databases.
In all cases, that person's job could have been replaced by a script. It's just that no-one had the imagination to realise it.
I'm sure that there are many ways in which the solution can be implemented, but for me they are all covered by this process:
• Divide your database changes into:
• Things that can be ran many times without causing damage.
• Things that can only be ran once.
• Make sure that you have a structure that ensures that the things that can only be run once, only run once, and all the rest run every time.
When it comes to making a build:
• Find out which things need running
• Run them, in the right order
• Stop when you get an error
For our Oracle build, this basically translates to a build script that incorporates 2 parts:
First we have a patch runner. A generic script runner that will take an ordered list of scripts and ensure that every one of those scripts runs against the database once, and no more than once. If any of the scripts cause an exception then the whole thing stops.
These scripts basically consist of table and data changes: the only components of an Oracle build script that we need to ensure only run once.
The patches and the patch list are held in version control, along with the rest of the source code, so if we want to take a database up to version 2.4.5, we just check out version 2.4.5 and tell the patch runner to run. The patch list only contains those patches that were part of 2.4.5, and the patch runner makes sure it only installs the patches that have not already been run.
Is it happens, we add another level of complexity on top of that. For every patch we have an additional 3 scripts. We have two that check the pre and post conditions for a patch. The pre conditions embody the assumptions that are made about the state of the database before the patch can be ran. The pre conditions are tested, and if they fail the patch doesn't run. That way, instead of picking apart data that has been mangled by a patch that should not have ran, we can look at a database to determine why the conditions required for the patch weren't met. A much easier proposition. When the patch is completed the post conditions are checked. These state the success
conditions of the patch and ensure that when a patch is ran it does what was intended. Again, if the conditions aren't met then the upgrade stops.
The third script is the reversal script. This can be used in a disaster recovery situation, when a patch has completed but must be removed. All four scripts are produced by a single developer... the one that requires the database to change.
Second in the build, we have a script that re-installs absolutely everything else.
Every view, trigger, package, procedure, function in the system is re-created, every time. You don't need someone to work out which packages have changed and ensure they get added to the build script if you always install everything. And what harm is done by always installing everything? It might take extra time to run the script, but the advantage is that the only thing the build script cares about is the target
version... not the source version.
Of course, the detail of the build script is more complicated than that, but that's the basic structure described. And with that structure we can take any version of the system and upgrade it to any other version. We can take an empty database and build the system in less than 5 minutes.
And we use that fact to give ourselves the best present a developer can have...
A Sandbox.
Make yourself a sandbox to play inEvery decent developer I've worked with understands that you don't just dive in and make changes on a live server, and they all buy into the basic idea of version control for files.
People instinctively get the idea:
"If I'm working on this particular file then I want to be sure that I
am the only person updating this file.
When I save it and close it I need to know that when I open it
again it'll be the same file.
I need to know that I'm working in isolation."
When you're developing, you need to have your own version of the source code you're changing, and have complete control over it.
Version control tools like CVS and Subversion take this a step further and give you a private copy of the whole application. That way you can change any source code file and know that the changes you've made are private to you.
Sometimes this idea is called 'the workspace', other times it's 'a sandbox'. Both are basically the same thing, but I like the metaphor of the sandbox... it's simple:
I'm in my sandbox.
I'm safe from the rest of the world and the rest of the world is safe from me.
I can play.
The idea is phenomenally successful when applied to source code. Probably because it's simply an extension of what any decent developer would instinctively do. That's why I'm so surprised that I so rarely see the idea extended to databases.
I've worked at a few places where I got my own set of source code to play with, but invariably I had to install it into a database that was shared between the development team.
Sometimes that DB would be specific to a branch on the development tree, other times it would just be a single conglomeration of all the different versions in an unstructured mass.
It's like giving yourself a sandbox... and then putting it too close to the swings.
You can be happily playing away, safe in the knowledge that you're completely unaffected by what other people are doing and BANG, another developer:
• Updates the database, wiping out your test data
• Overwrites your piece of code
• Or even worse, introduces a subtle bug into some code that you use but haven't changed... you spend hours nursing your bad head, trying to track it down, and then find that the bug mysteriously disappears again.
You think you're in isolation, but you're not.
Once you get used to the fact that your world can change around you without warning, then you get more and more likely to assume that the bugs you see in your development are not your fault.
The natural reaction is to blame the weakest link, and you'd never dream of accepting that you might be that link. Working in real isolation means that there's no ambiguity... you are the only link.
Sandboxes have to be complete, or they're use is seriously compromised, and they're only complete if you have your own database.
If you have your own database you can treat it fully as your own, and know that any changes that occur to it occur because you made them.
When you need to integrate with development trunk you follow the simple pattern.. update your sandbox files, run the database upgrade and test.
When you update your sandbox you're updating both the application source code and the build script, and since an idiot can run your build script then you can upgrade your database with no fuss.
Not only are you using your sandbox to separate yourself from the rest of world, but you're also using it test your build script. If you have 10 developers working in 10 sandboxes then you immediately have 10 build testers as well.
Traditionally, as the number of developers increases, then the fragility of the build also increases: since the build is changing more frequently it's more likely to break. But if every one of those developers is testing the build as they go along, then you can maintain the quality.
Obviously, this kind of informal testing is no replacement for full blown testing, but any testing increases quality.
So my argument is that I've if you've got 10 developers (or 10 pairs if you're doing it the XP way), then you need 10 databases...
Now I can hear DBAs screaming: for most DBA's I've probably at least doubled the number of databases they manage. But it's not as bad as all that once you take a look at what a development database should actually be.
The worry comes from the thought that a development database is the same species of beast as the live database. It isn't, not by a long way.
The major difference between a live and development database is how their role defines the use of data. In a live database the single most important thing in that database is the data it holds. It is the sole purpose for the existence of that database. The live database without the live data is useless.
In the development environment this is not the case; the most important thing in a development database is its structure.
Its purpose is to work as a validation tool for the live database, to ensure that the application we're producing works against the live database and to allow us to develop the structure of that database in order to allow to us to develop the applications.
It's important that we hold data that has a texture similar to that which exists in live, but it doesn't matter which data we hold. The data itself has no intrinsic value. We can generate our own.
In fact, when we run unit tests on our PL/SQL code, this is exactly what we do; we generate our test data so we know exactly what form it is in. That way we can make clear statements about the form we expect it to be in when our PL/SQL has completed.
We then use this generated test data as the normal data for our development. By clearing down and recreating test data regularly we are sure that any bugs we see in our development environment are caused by our code, not by some out of date and twisted set of data that was created by someone else half way though some development.
Also, we don't need to hold the same volume of data. In live, every single piece of data is of importance and so you can't just remove it. In development we can limit ourselves to create only the data that is of importance to us at this point in time.
If our development databases contain a very small amount of data, and the means to re-generate the data it needs, then you remove a large amount of the DBA's work.
That is, most the work a DBA will do in maintaining a live database is purely down to the fact that it is a system that contains a large volume of critical data. It must always be available, it must serve data within certain performance requirements, and if the machine it's running on suddenly blows up then we must be able to recover the data. Quickly.
Take away all that away and you've taken away most of the DBA's work in maintaining that database.
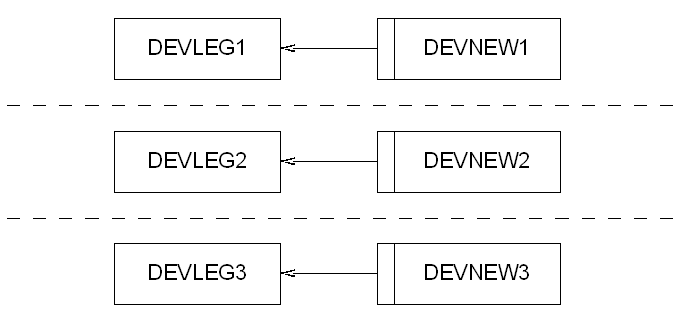
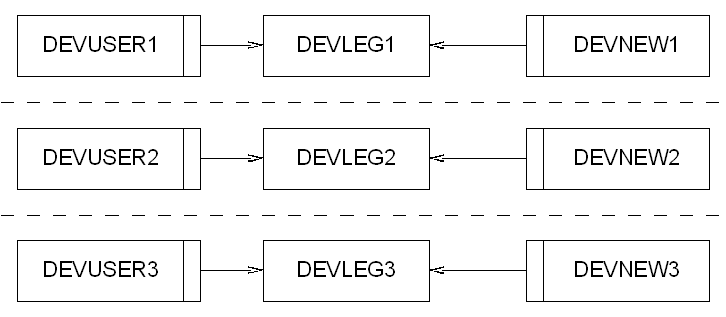
So the approach we've taken is to get the DBA to create a single development database instance, and then within that we've created several independent schemas. Each schema is owned by a particular developer and they're responsible for the state of that schema.
Each schema contains a mirror of the structure of the live system, with any changes that the latest bits of development have created. Each schema is a completely self contained working version of the system.
OK, so the structure of the development workspace is slightly different to that of the live system; the live system has only the one application schema on each database instance, but we hide all that in the build script. The build script itself understands what type of database it's installing and changes its behaviour when we're upgrading a development database. As it happens, the only real change is replacing public synonyms with private synonyms for some objects, and then installing
the test suite.
I admit that it took a bit of work to get the structures right, and in making sure that differences between live and development were as small as possible but now that we have that structure in place we can create a new sandbox for a new developer in about 5 minutes... the amount of time it takes to run our build script. And every developer in the team can go into a sandbox and play, safe in the knowledge that NOTHING they do in that sandbox will affect anyone else.
I don't think there's a single developer in the team that would give it up.
ConclusionObviously, in the last 18 months there's been a lot of other lessons that I'd take onto another project, but the combination of good version control policy, a simple build script and individual developer sandboxes have had a fundamental impact on our day-to-day life.
The implementation of those foundations has allowed our developers to focus on the job at hand... the development of new a system. And it gives our DBA the confidence that the installation of a new version of the system won't cause him a weekend of headaches and pain. Rollouts of the system aren't trivial, and never will be. There are always going to be other project management issues to deal with... first line support and user training, for example. But we've got to a point where the actual upgrade of the database is not an issue.
The development team love the pair programming and unit testing aspects of XP, but without the sandboxes we'd still have a team working with the usual frustrations caused by not working in isolation. Morale definitely improves when everyone feels as though they're in charge of their own space.
And the solid version control policy allows us to manage the whole process of concurrent development without ever really thinking about it. We support live systems and develop new functionality side by side with very little pain.
All in all, these three things just make our jobs a hell of a lot easier. And let us focus on what we do best, and ultimately, what we're paid for. Developing new systems... and drinking coffee.
Technorati Tags: Oracle, development, software, XP, version+control, sandbox, workspace, UKOUG, OUG, Andrew+Clarke, Robert+Baillie, Sue+Harper, SQL+Developer