In our current project we're building an application that will eventually replace an existing one. Until it does so we need to ensure that our new application can live together with the legacy one, and will share the same data. The two systems must exist symbiotically.
The existing application, let's call it Legacy is a classic Forms or Powerbuilder and Oracle structure. All it's objects exist in the Oracle user LEGACY, and are wrapped in public synonyms.
Each users of the system is given an Oracle user that then accesses the LEGACY objects through the public synonyms. Let's say have the users USER1, USER2 and USER3.
So we have a structure that looks like this:
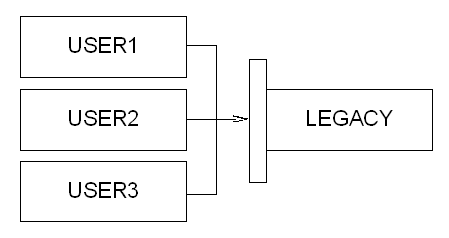
The new application is to live within the same database. We'll call that application NewApp, and install it into the new Oracle user NEWAPP. As an Intranet delivered system (over HTTP) we decided that all user connections to the Oracle database would occur through the user NEWAPP.
We decided that in order to insulate ourselves from Legacy, we would ensure that all access to the LEGACY objects would be done through a new set of private synonyms. As an aside, this allowed us to develop a kind of 'name space'. I.E. The private synonyms for the LEGACY objects are all prefixed with LE_. That way we can tell which are LEGACY objects and which are NEWAPP and reduce the chances of clashing object names.
Anyway, that then gives us the following structure in our live environment:

We then state that we do not add new functionality into the LEGACY user. I.E. All development for NewApp is done in the NEWAPP user. We are not the owners of LEGACY and therefore do not have the ability to change LEGACY at will. We are the owners of NEWAPP and therefore the contents of NEWAPP are entirely under our control.
So how do we deal with this structure in our workspaces?
One option is to build a full database per developer / pair. Starting with an empty database we could either import a copy of LEGACY or build one from scripts. Then by running our NewApp build script we can build the NEWAPP user as it would exist in the live environment.
This may be appropriate for a small team of highly Oracle skilled developers, but I'm not too sure.
With the large number of databases you then have an overhead in terms of maintaining those databases. You either need a development DBA on hand to troubleshoot problems on each database, or you need each developer to be capable of dealing with those problems such as the listener not starting up, upgrading the DB to 9.2.0.7 to match the live environment, etc. In addition, if each database is on a client machine, you run the risk of each database being configured in a slightly different way... being fiddled with by developers that don't necessarily understand the impact of settings being different in development as they are in live.
In short, I'm not too sure. I know it CAN work, and that it's far superior to not having individual workspaces... but we followed a different route.
We decided we wanted a single development database, in which many workspaces could exist. However, in order to have individual workspaces, we don't just need individual NEWAPP users, we also need individual LEGACY users. OK, so we may not be changing the structure or functionality of the LEGACY user, but much of our data exists in that user. If we're to be insulated from the changes made in other workspaces, then we need to be insulated from data changes as well as structural ones.
So how do we implement the individual workspaces in a single database?
The answer is actually surprisingly simple; we have a dual mode build script, to which we can state that we're building a development environment.
If we're building into live / demo / any other non development environment then we build our private synonyms and issue our grants to LEGACY objects, then build / upgrade the NEWAPP user.
If we're building into a development environment then we start off by creating our development version of the LEGACY user (lets call it DEVLEG1), then create our private synonyms and grants to DEVLEG1 instead of LEGACY.
So if we were to build the development environments DEVNEW1/DEVLEG1, DEVNEW2/DEVLEG2 and DEVNEW3/DEVLEG3 then we'd have the following structures:
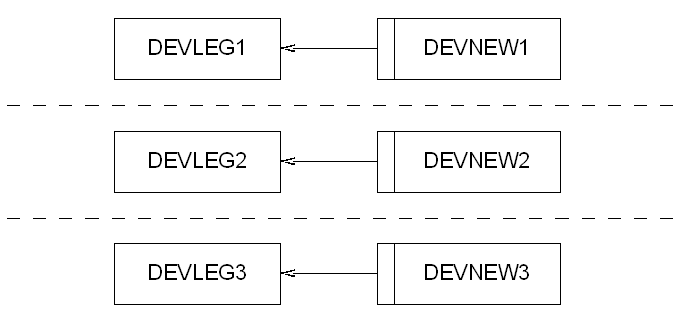
If we then found that we needed to be able run the front end for Legacy in our development environments then we could add the creation of relevant users along with private synonyms to the appropriate DEVLEGx user, giving us the following structures:
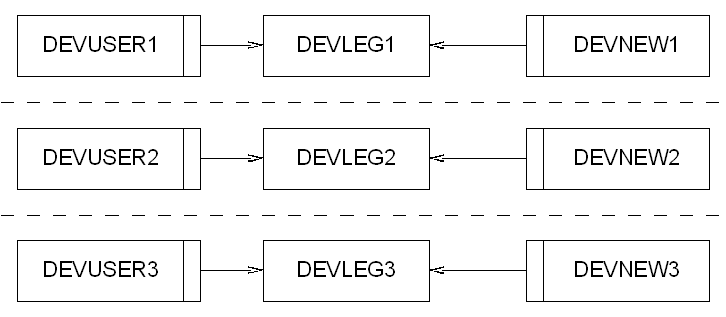
The result is that we have fully independant development workspaces whilst allowing the database to be centrally managed. We can use our DBA team to keep the databases up and running and control the set-up whilst allowing us to develop the code freely without treading on each other's toes.
The eagle eyed of you may notice the fact that our development databases may be a little deviod of data, not a great scenario. However, we have noticed that ourselves and put a solution in place. More on that later...
Technorati Tags: Oracle, software, development, database, upgrade, blog, agile, Robert+Baillie, patch, db, dbms, workspaces, sandboxes